ผมได้พยายามทำความเข้าใจ buzzword ใหม่ล่าสุดในวงการ AI coding อย่างหนึ่ง นั่นก็คือ Spec-driven development (SDD) ผมได้ลองดูเครื่องมือสามตัวที่เรียกตัวเองว่าเป็น SDD tool และพยายามจะแกะว่ามันหมายความว่าอะไร ณ เวลานี้
Definition (นิยาม)
เช่นเดียวกับคำศัพท์เกิดใหม่หลายคำในวงการที่เปลี่ยนแปลงอย่างรวดเร็วนี้ นิยามของ "spec-driven development" (SDD) ยังคงไม่ชัดเจน นี่คือสิ่งที่ผมพอจะรวบรวมได้จากวิธีที่เห็นคนใช้นิยามนี้มาจนถึงตอนนี้ Spec-driven development คือการเขียน "spec" ก่อนที่จะเขียนโค้ดด้วย AI ("documentation first") โดย spec จะกลายเป็น source of truth สำหรับทั้งมนุษย์และ AI
GitHub: "ในโลกใหม่นี้ การบำรุงรักษาซอฟต์แวร์หมายถึงการพัฒนา spec [...] ภาษากลางของการพัฒนาซอฟต์แวร์ขยับไปอยู่ในระดับที่สูงขึ้น และโค้ดก็กลายเป็นแค่ขั้นตอนสุดท้าย (last-mile approach)"
Tessl: "แนวทางการพัฒนาที่ spec — ไม่ใช่โค้ด — เป็น artifact หลัก โดย Spec จะอธิบาย intent ในภาษาที่มีโครงสร้างและสามารถทดสอบได้ และ agent จะสร้างโค้ดขึ้นมาให้ตรงตาม spec นั้น"
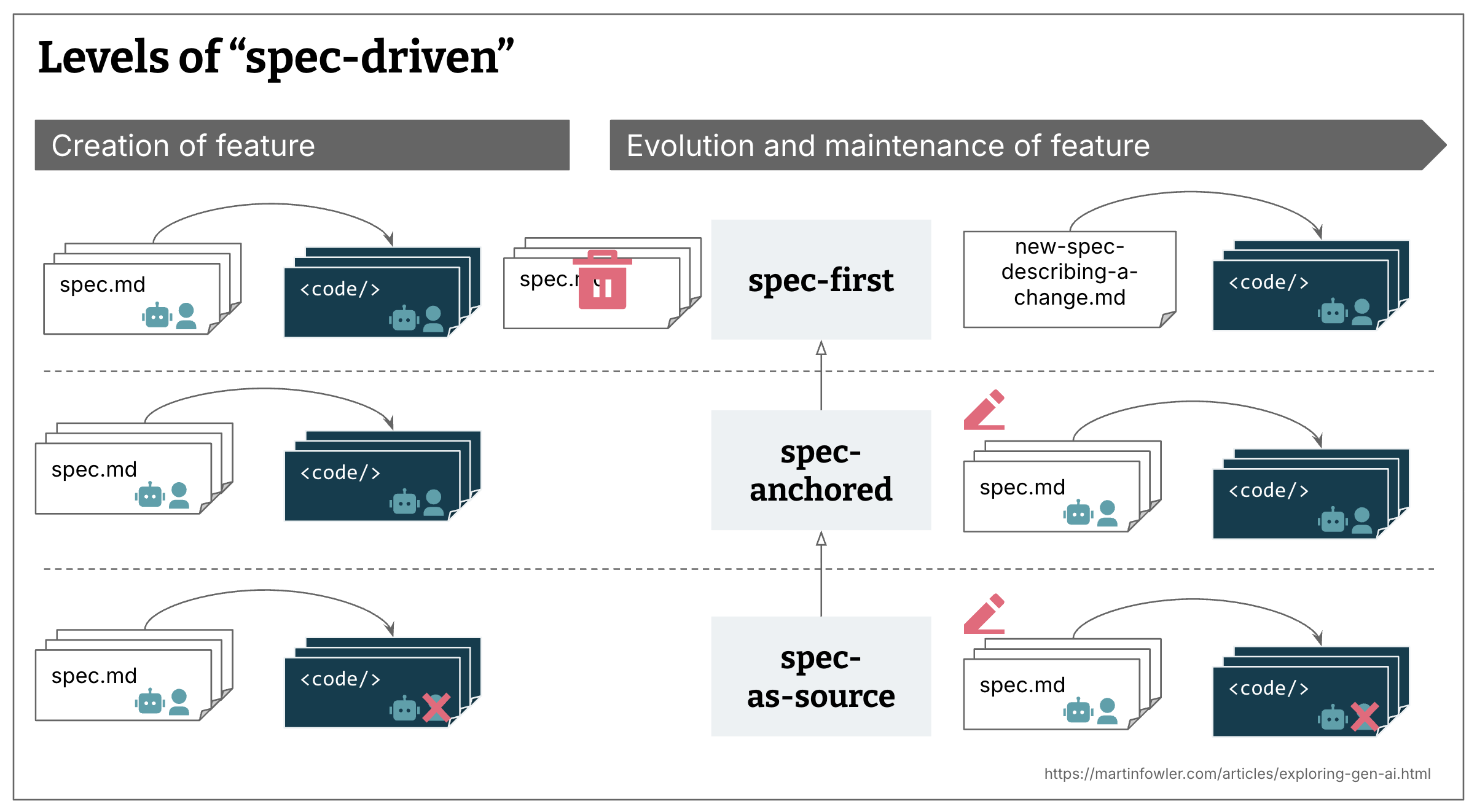
หลังจากดูวิธีการใช้งานของเทอมนี้ และเครื่องมือบางตัวที่อ้างว่านำ SDD มาใช้ ดูเหมือนว่าในความเป็นจริงแล้ว มันมีระดับของการนำไปใช้งานที่แตกต่างกันหลายระดับ:
- Spec-first: เขียน spec ที่คิดมาอย่างดีก่อน จากนั้นจึงนำไปใช้ใน workflow การพัฒนาด้วย AI สำหรับงานนั้นๆ
- Spec-anchored: Spec จะถูกเก็บไว้แม้หลังจากทำงานเสร็จแล้ว เพื่อนำมาใช้ต่อในการพัฒนาและบำรุงรักษา feature นั้นๆ ในภายหลัง
- Spec-as-source: Spec คือไฟล์หลักที่ถูกแก้ไขตลอดอายุของระบบ โดยมนุษย์จะแก้เฉพาะ spec เท่านั้น และไม่ต้องแตะโค้ดเลย
แนวทาง SDD และนิยามทั้งหมดที่ผมเจอล้วนเป็น spec-first แต่ไม่ใช่ทั้งหมดที่จะพยายามเป็น spec-anchored หรือ spec-as-source และบ่อยครั้งที่มันถูกปล่อยให้คลุมเครือหรือเปิดกว้างโดยสมบูรณ์ว่ากลยุทธ์การบำรุงรักษา spec ในระยะยาวควรจะเป็นอย่างไร
What is a spec? (spec คืออะไร)
แน่นอนว่าคำถามสำคัญในเรื่องนิยามก็คือ: Spec คืออะไร? ดูเหมือนจะไม่มีนิยามที่เป็นกลาง สิ่งที่ใกล้เคียงกับนิยามที่สอดคล้องกันมากที่สุดคือการเปรียบเทียบ spec กับ "Product Requirements Document"
คำนี้ค่อนข้างมีความหมายทับซ้อนกันมากในตอนนี้ นี่คือความพยายามของผมในการนิยามว่า spec คืออะไร:
Spec คือ artifact ที่มีโครงสร้างและเน้นพฤติกรรม — หรือชุดของ artifacts ที่เกี่ยวข้องกัน — ที่เขียนด้วยภาษาธรรมชาติ (natural language) เพื่ออธิบายฟังก์ชันการทำงานของซอฟต์แวร์ และทำหน้าที่เป็นแนวทางให้กับ AI coding agents แต่ละ variant ของ spec-driven development จะนิยามแนวทางของตนเองในเรื่องโครงสร้างของ spec ระดับของรายละเอียด และวิธีการจัดระเบียบ artifacts เหล่านี้ภายในโปรเจกต์
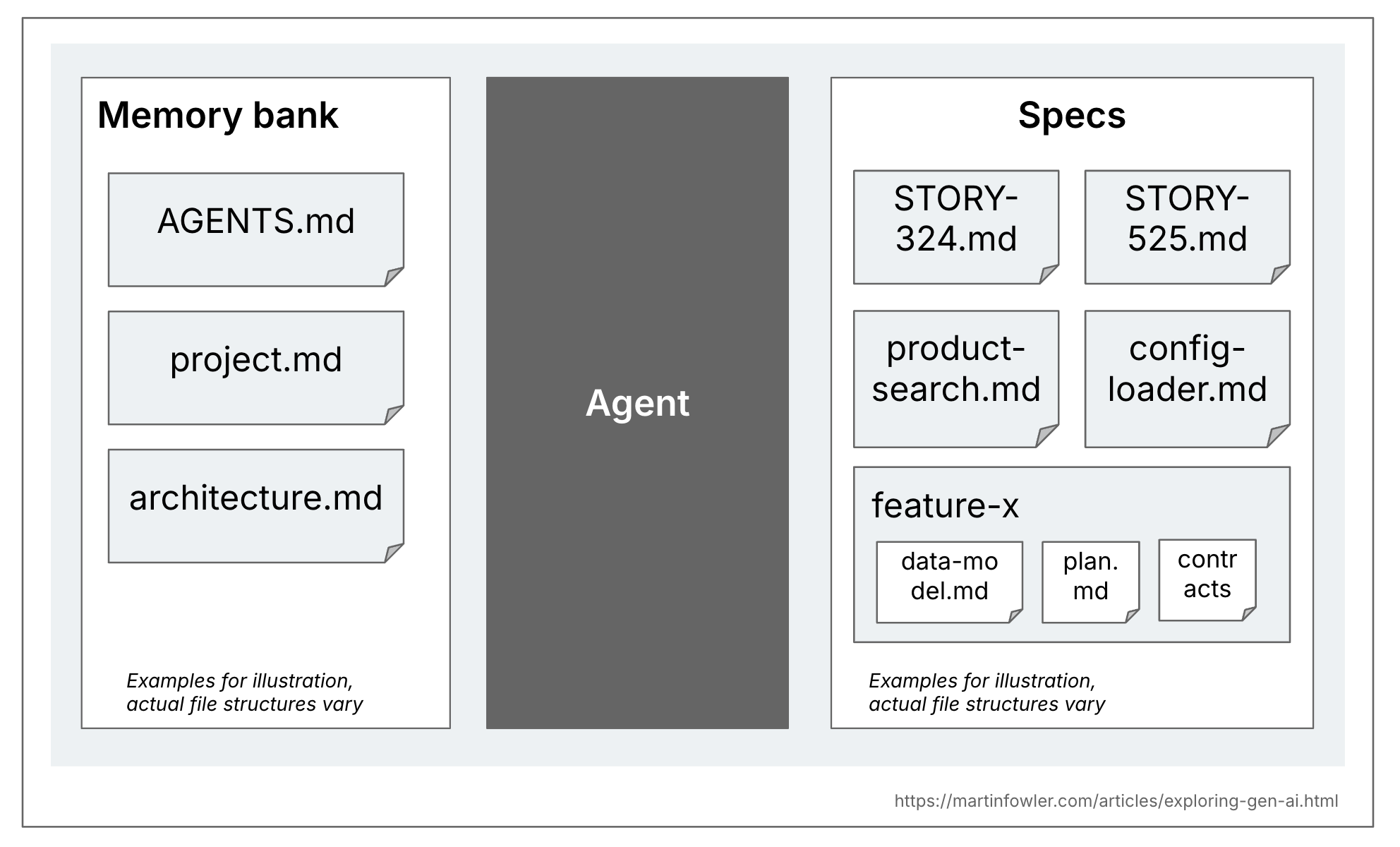
ผมคิดว่ามีความแตกต่างที่มีประโยชน์ระหว่าง spec กับ context documents ทั่วไปของ codebase context ทั่วไปนั้นคือพวก rules file หรือคำอธิบายระดับสูงของ product และ codebase บางเครื่องมือเรียก context นี้ว่า memory bank ดังนั้นผมจะใช้คำนี้ในที่นี้ ไฟล์เหล่านี้มีความเกี่ยวข้องในทุกๆ AI coding session ใน codebase ในขณะที่ spec จะเกี่ยวข้องเฉพาะกับงานที่สร้างหรือเปลี่ยนแปลงฟังก์ชันการทำงานนั้นๆ เท่านั้น
The challenge with evaluating SDD tools (ความท้าทายในการประเมิน SDD tools)
ปรากฏว่าการประเมิน SDD tools และแนวทางต่างๆ ในแบบที่ใกล้เคียงกับการใช้งานจริงนั้นใช้เวลาค่อนข้างมาก คุณจะต้องลองใช้มันกับปัญหาขนาดต่างๆ ทั้ง greenfield และ brownfield และต้องใช้เวลาจริงๆ ในการทบทวนและแก้ไข artifacts ระหว่างทางมากกว่าแค่ดูผ่านๆ เพราะดังที่ บล็อกโพสต์ของ GitHub เกี่ยวกับ spec-kit กล่าวไว้ว่า: "สิ่งสำคัญคือ บทบาทของคุณไม่ใช่แค่การนำทาง แต่คือการตรวจสอบ ในแต่ละเฟส คุณต้องไตร่ตรองและปรับปรุง"
สำหรับสองในสามเครื่องมือที่ผมลอง ดูเหมือนว่าการนำพวกมันเข้าไปใช้ใน codebase ที่มีอยู่แล้วนั้นเป็นงานที่หนักกว่าเดิมอีก ทำให้ยิ่งยากขึ้นไปอีกที่จะประเมินประโยชน์ของมันสำหรับ brownfield codebases จนกว่าผมจะได้ยินรายงานการใช้งานจากคนที่ใช้มันเป็นระยะเวลาหนึ่งบน codebase "จริง" ผมยังคงมีคำถามที่ยังไม่ได้คำตอบอีกมากมายว่ามันทำงานได้ดีในชีวิตจริงแค่ไหน
ถึงอย่างนั้น — มาดูสามเครื่องมือนี้กันดีกว่า ผมจะแชร์คำอธิบายก่อนว่ามันทำงานยังไง (หรือพูดให้ถูกคือ ผมคิดว่ามันทำงานยังไง) และจะเก็บข้อสังเกตและคำถามของผมไว้ตอนท้าย ขอเตือนไว้ก่อนว่าเครื่องมือเหล่านี้พัฒนาเร็วมาก ดังนั้นมันอาจจะเปลี่ยนไปแล้วตั้งแต่ตอนที่ผมใช้มันในเดือนกันยายน
Kiro
Kiro เป็นเครื่องมือที่เรียบง่ายที่สุด (หรือเบาที่สุด) ในสามตัวที่ผมลอง ดูเหมือนว่ามันจะเป็น spec-first เป็นหลัก ตัวอย่างทั้งหมดที่ผมเจอใช้มันสำหรับงานเดียว หรือ user story เดียว โดยไม่มีการพูดถึงวิธีใช้ requirements document ในลักษณะ spec-anchored เมื่อเวลาผ่านไป ข้ามหลาย tasks
Workflow: Requirements → Design → Tasks
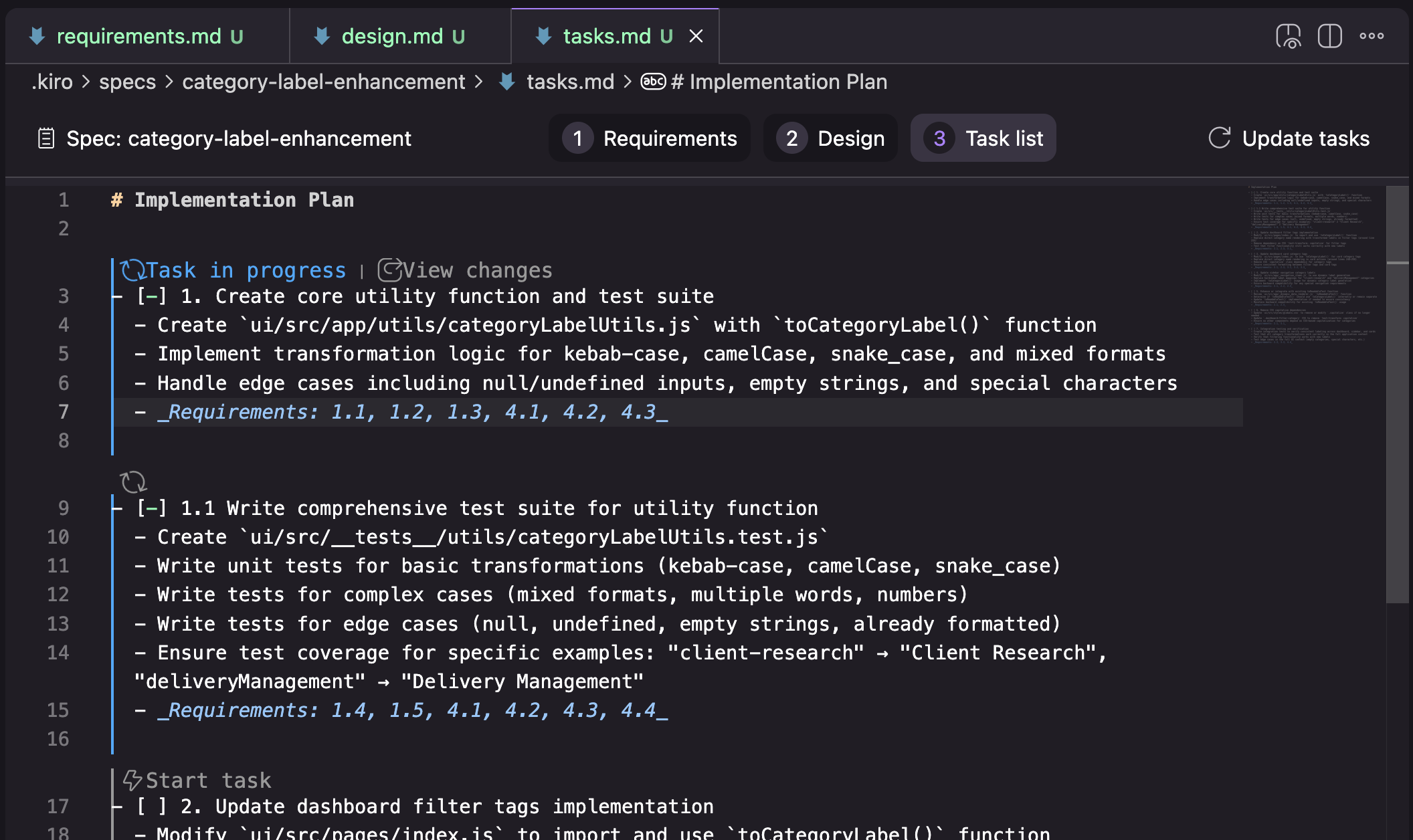
แต่ละขั้นตอนของ workflow จะแสดงด้วย markdown document หนึ่งฉบับ และ Kiro จะนำคุณผ่าน 3 ขั้นตอนเหล่านั้นภายใน VS Code distribution ของมัน
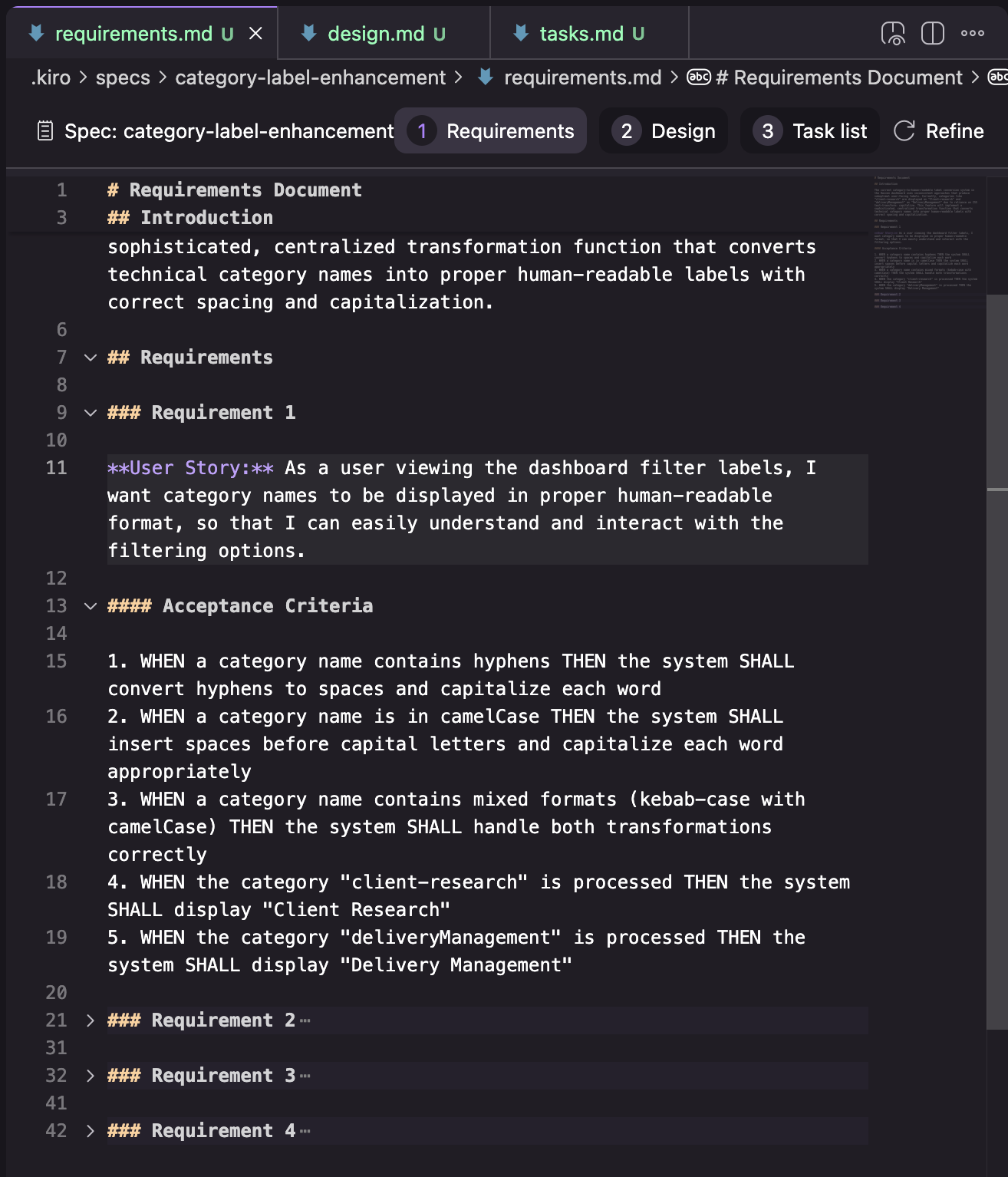
Requirements: มีโครงสร้างเป็นรายการของ requirements โดยแต่ละ requirement จะแทน "User Story" (ในรูปแบบ "As a…") พร้อม acceptance criteria (ในรูปแบบ "GIVEN… WHEN… THEN…")
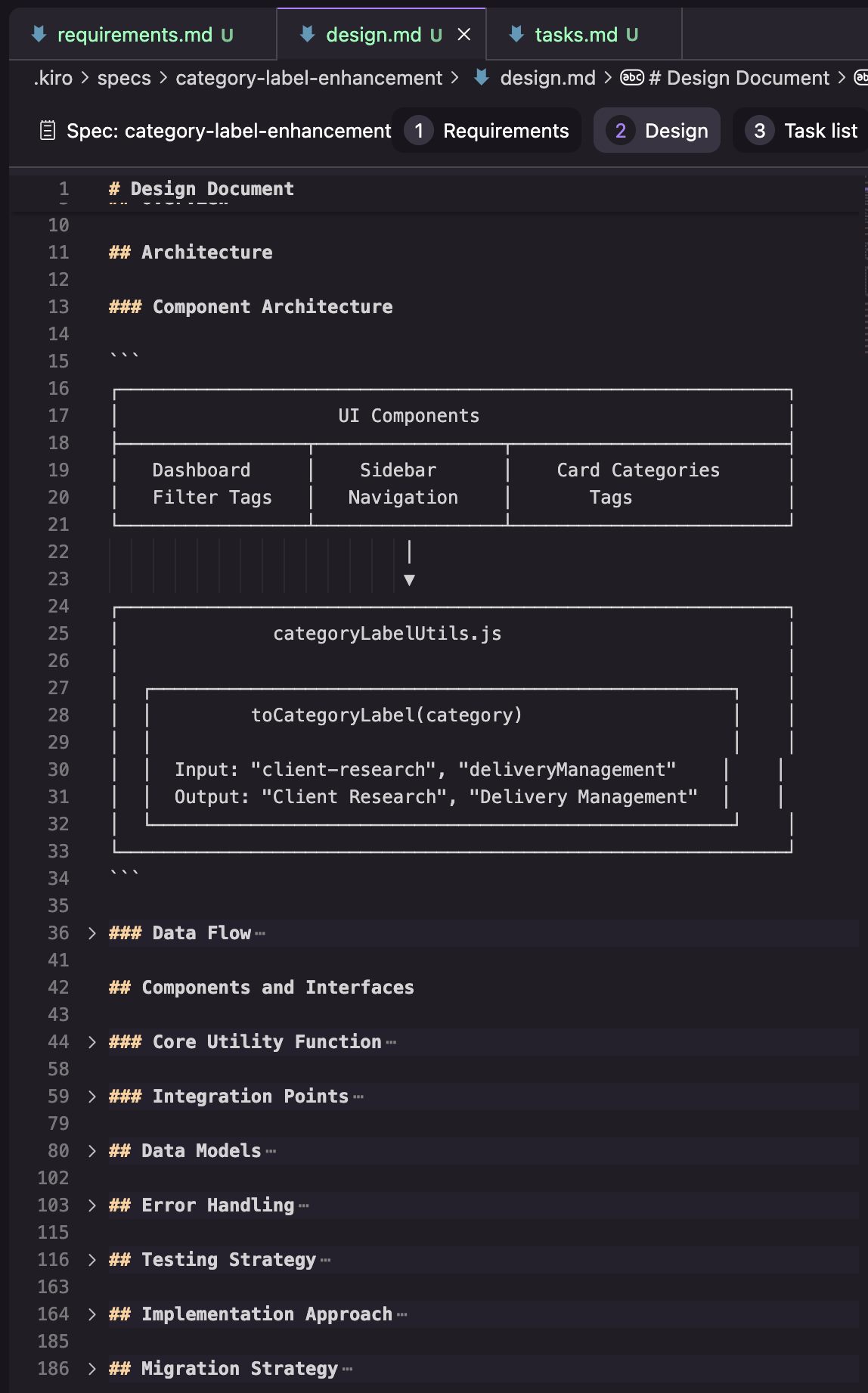
Design: ในการลองใช้ของผม เอกสาร design ประกอบไปด้วยส่วนต่างๆ ที่เห็นในภาพหน้าจอด้านล่าง ผมมีแค่ผลลัพธ์จากการลองครั้งเดียวเท่านั้น ดังนั้นผมไม่แน่ใจว่านี่เป็นโครงสร้างที่ตายตัวหรือเปล่า หรือมันเปลี่ยนไปตาม task
Tasks: รายการของ tasks ที่โยงกลับไปยังหมายเลข requirements และมี UI elements เพิ่มเติมสำหรับการรัน tasks ทีละรายการ และตรวจสอบการเปลี่ยนแปลงในแต่ละ task
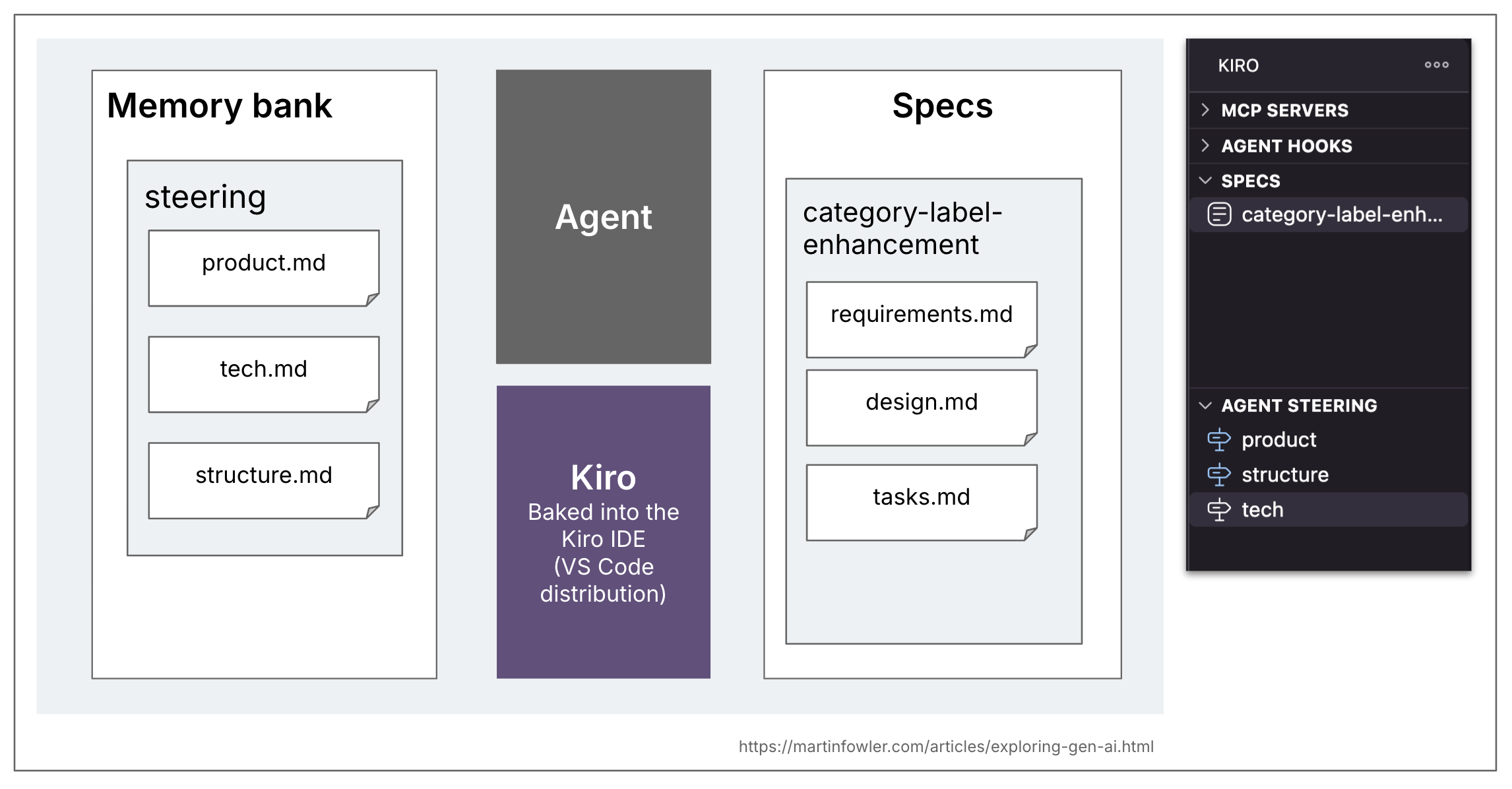
Kiro ยังมีแนวคิดเรื่อง memory bank ด้วย โดยเขาเรียกมันว่า "steering" เนื้อหาของมันมีความยืดหยุ่น และ workflow ของพวกเขาดูเหมือนจะไม่พึ่งพาไฟล์เฉพาะใดๆ (ผมลองใช้มันก่อนที่จะค้นพบส่วน steering ซะอีก) โครงสร้างเริ่มต้นที่ Kiro สร้างขึ้นเมื่อคุณขอให้มัน generate steering documents คือ product.md, structure.md, tech.md
Spec-kit
Spec-kit คือเวอร์ชัน SDD ของ GitHub มันถูกแจกจ่ายเป็น CLI ที่สามารถสร้าง workspace setups สำหรับ coding assistants หลากหลายชนิดได้ เมื่อตั้งค่าโครงสร้างนั้นแล้ว คุณจะโต้ตอบกับ spec-kit ผ่าน slash commands ใน coding assistant ของคุณ เนื่องจาก artifacts ทั้งหมดของมันถูกวางไว้ใน workspace ของคุณโดยตรง มันจึงเป็นเครื่องมือที่ปรับแต่งได้มากที่สุดในสามตัวที่พูดถึงในบทความนี้
Workflow: Constitution → 𝄆 Specify → Plan → Tasks 𝄇
แนวคิด memory bank ของ Spec-kit เป็นข้อกำหนดเบื้องต้นสำหรับแนวทาง spec-driven โดยเขาเรียกมันว่า constitution constitution มีไว้เพื่อเก็บหลักการระดับสูงที่ "ไม่เปลี่ยนแปลง" และควรถูกนำไปใช้กับทุกการเปลี่ยนแปลงเสมอ โดยพื้นฐานแล้วมันคือ rules file ที่ทรงพลังมาก ซึ่งถูกใช้อย่างหนักใน workflow
ในแต่ละขั้นตอนของ workflow (specify, plan, tasks) spec-kit จะสร้างชุดของไฟล์และ prompts ด้วยความช่วยเหลือของ bash script และ templates บางส่วน จากนั้น workflow จะใช้ checklists ภายในไฟล์เหล่านั้นอย่างหนัก เพื่อติดตามคำชี้แจงที่จำเป็นจากผู้ใช้ การละเมิด constitution งานวิจัย ฯลฯ พวกมันเหมือน "นิยามของความสำเร็จ" สำหรับแต่ละขั้นตอนของ workflow (แม้ว่าจะถูกตีความโดย AI ดังนั้นจึงไม่มีการรับประกัน 100% ว่าจะถูกรักษาไว้)
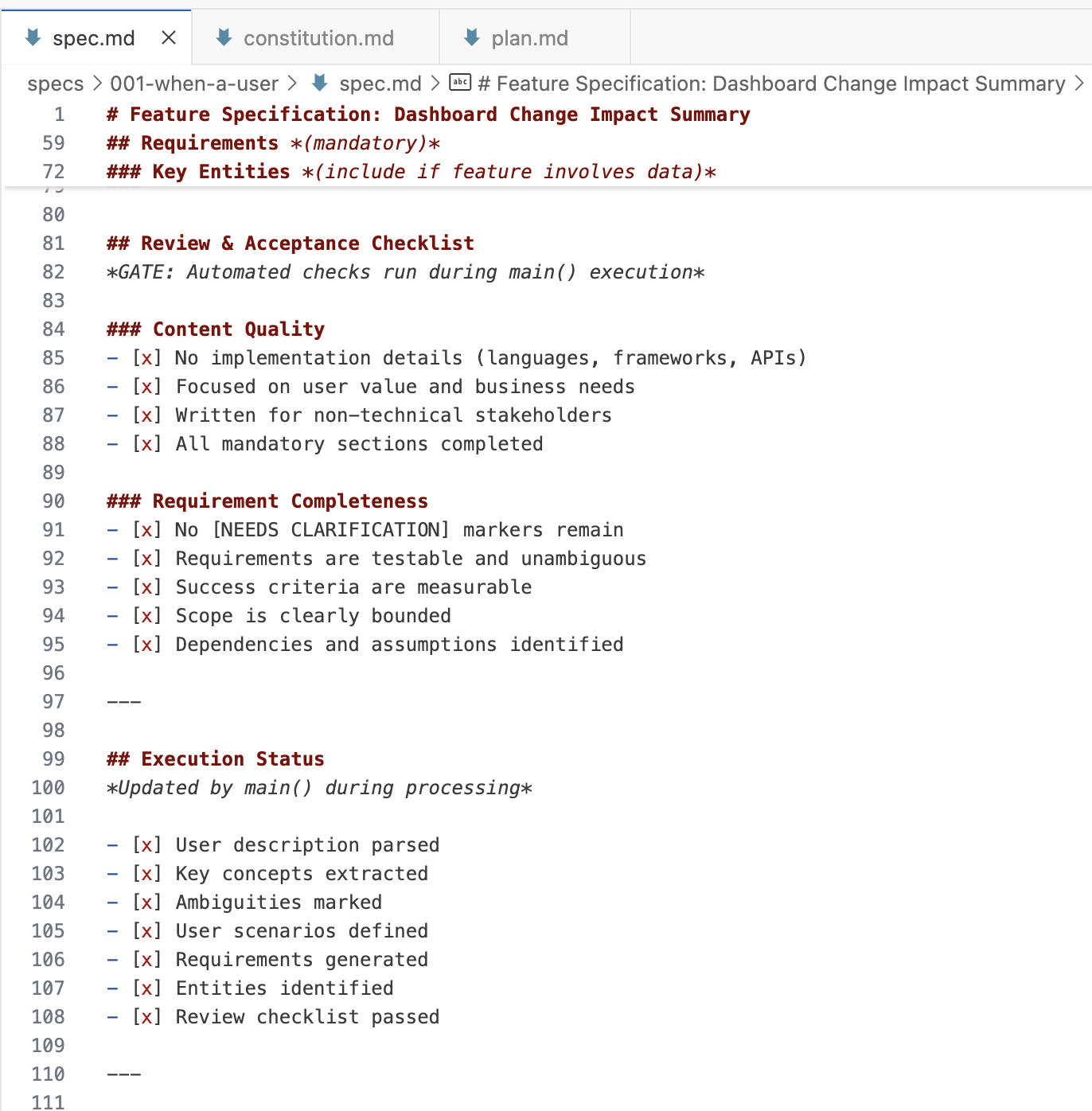
ด้านล่างคือภาพรวมเพื่อแสดง file topology ที่ผมเห็นใน spec-kit สังเกตว่า spec หนึ่งๆ ประกอบไปด้วยหลายไฟล์
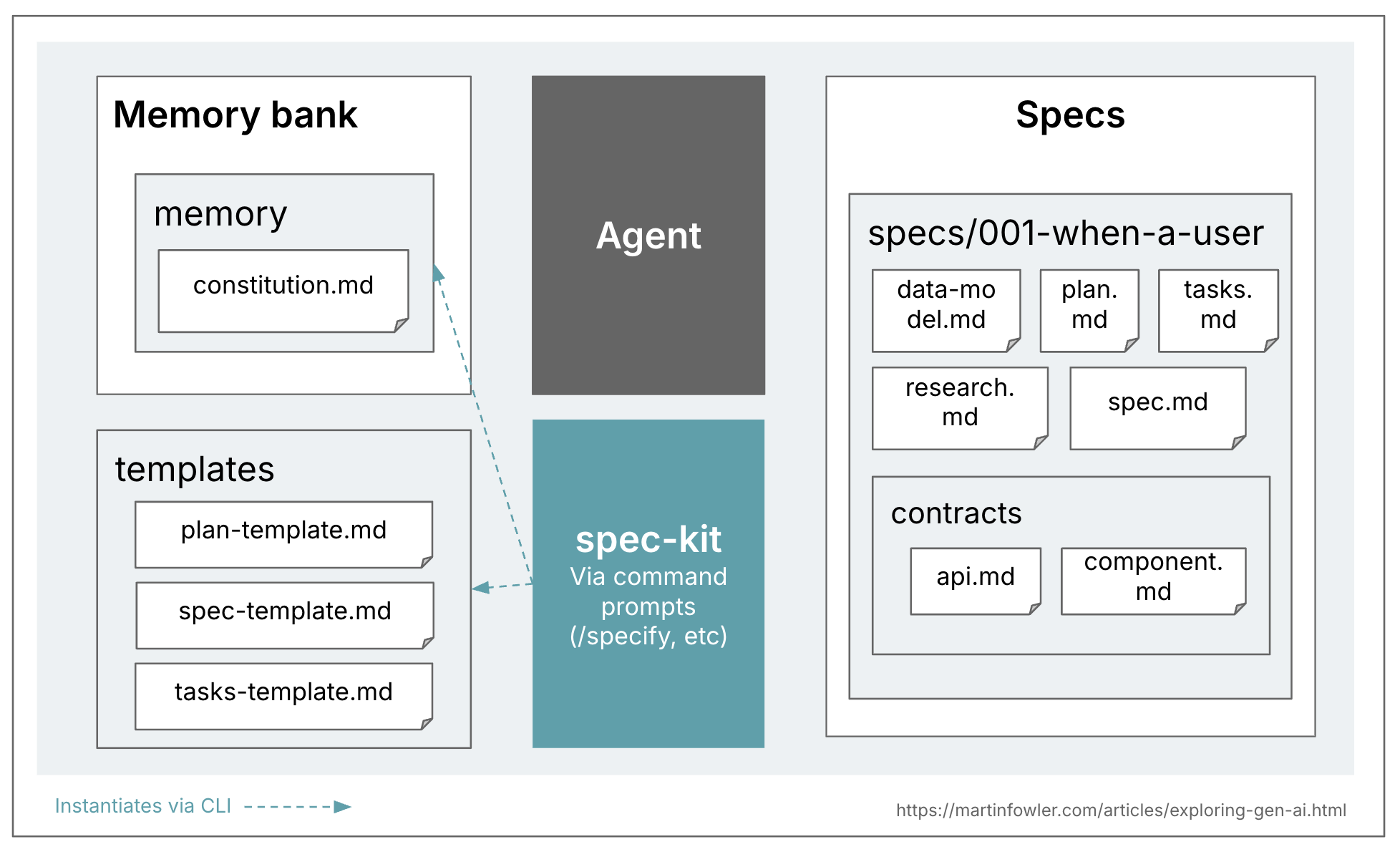
เมื่อมองดูเผินๆ GitHub ดูเหมือนจะตั้งเป้าไปที่แนวทาง spec-anchored ("นั่นคือเหตุผลที่เรากำลังคิดใหม่เกี่ยวกับ specifications — ไม่ใช่เป็นเอกสารคงที่ แต่เป็น artifacts ที่มีชีวิตและสามารถพัฒนาไปพร้อมกับโปรเจกต์ Specs กลายเป็น source of truth ร่วมกัน เมื่อมีอะไรที่ไม่สมเหตุสมผล คุณกลับไปที่ spec เมื่อโปรเจกต์ซับซ้อนขึ้น คุณก็ปรับปรุงมัน เมื่อ tasks ใหญ่เกินไป คุณก็แยกย่อยมัน") อย่างไรก็ตาม spec-kit จะสร้าง branch ใหม่ทุกครั้งที่มีการสร้าง spec ซึ่งดูเหมือนจะบ่งชี้ว่าพวกเขามอง spec เป็น artifact ที่มีชีวิตตลอดอายุของ change request ไม่ใช่ตลอดอายุของ feature การสนทนาในชุมชนนี้กำลังพูดถึงความสับสนนี้ มันทำให้ผมคิดว่า spec-kit ยังคงเป็นแค่ spec-first เท่านั้น ไม่ใช่ spec-anchored ในระยะยาว
Tessl Framework
(ยังอยู่ใน private beta)
เช่นเดียวกับ spec-kit Tessl Framework ถูกแจกจ่ายเป็น CLI ที่สามารถสร้างโครงสร้าง workspace และ config ที่จำเป็นสำหรับ coding assistants หลากหลายชนิด โดยคำสั่ง CLI นี้ยังทำหน้าที่เป็น MCP server ได้ด้วย
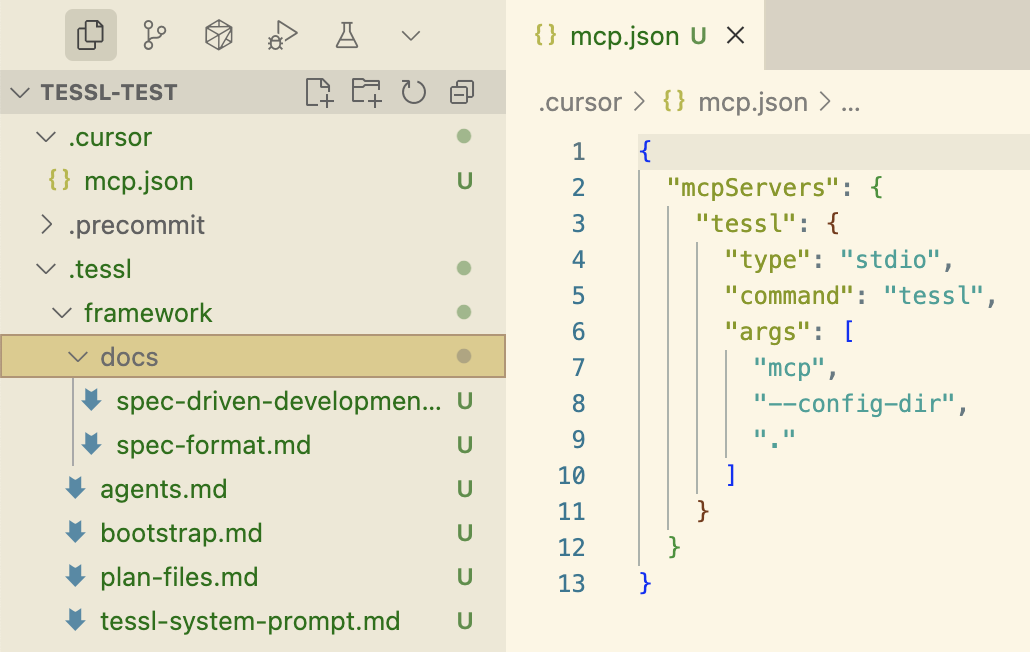
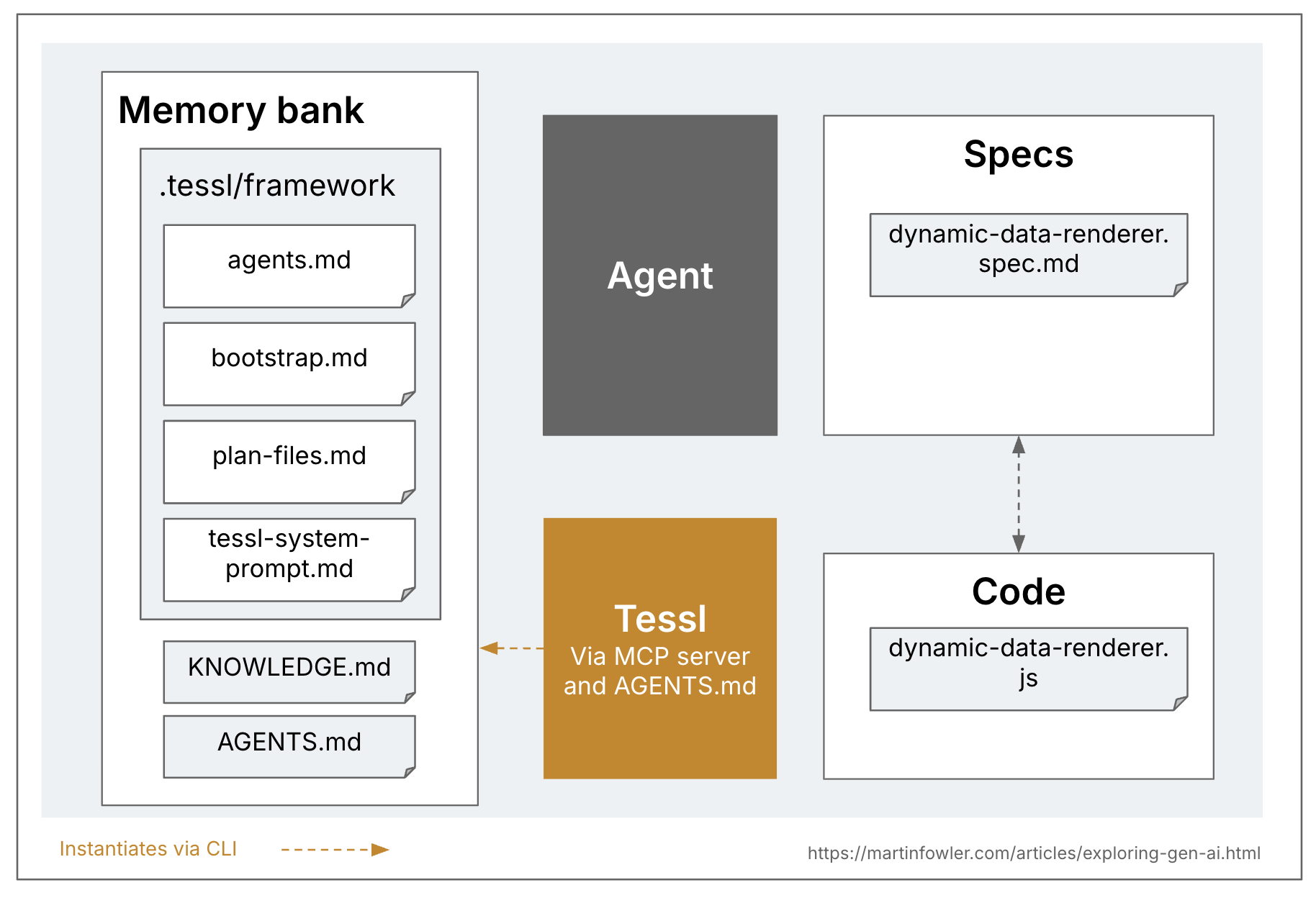
Tessl เป็นเพียงเครื่องมือเดียวในสามตัวนี้ที่ตั้งเป้าอย่างชัดเจนไปที่แนวทาง spec-anchored และยังกำลังสำรวจระดับ spec-as-source ของ SDD อีกด้วย Tessl spec สามารถทำหน้าที่เป็น artifact หลักที่ถูกบำรุงรักษาและแก้ไข โดยโค้ดจะมีคอมเมนต์กำกับไว้ที่ด้านบนว่า // GENERATED FROM SPEC - DO NOT EDIT ปัจจุบันนี่เป็นการ mapping แบบ 1:1 ระหว่าง spec และ code files กล่าวคือ หนึ่ง spec จะแปลเป็นหนึ่งไฟล์ใน codebase แต่ Tessl ยังอยู่ในช่วง beta และพวกเขากำลังทดลองกับเวอร์ชันต่างๆ ของแนวทางนี้ ดังนั้นผมจึงจินตนาการได้ว่าแนวทางนี้ยังสามารถถูกนำไปใช้ในระดับที่ spec หนึ่ง map ไปยัง code component ที่มีหลายไฟล์ได้ ยังคงต้องรอดูว่าตัว alpha product จะรองรับอะไรได้บ้าง (ทีม Tessl เองมองว่า framework ของพวกเขาเป็นสิ่งที่อยู่ในอนาคตมากกว่าผลิตภัณฑ์สาธารณะปัจจุบันของพวกเขาอย่าง Tessl Registry)
นี่คือตัวอย่างของ spec ที่ผมให้ Tessl CLI ทำ reverse engineer (tessl document --code ...js) จากไฟล์ JavaScript ใน codebase ที่มีอยู่แล้ว:
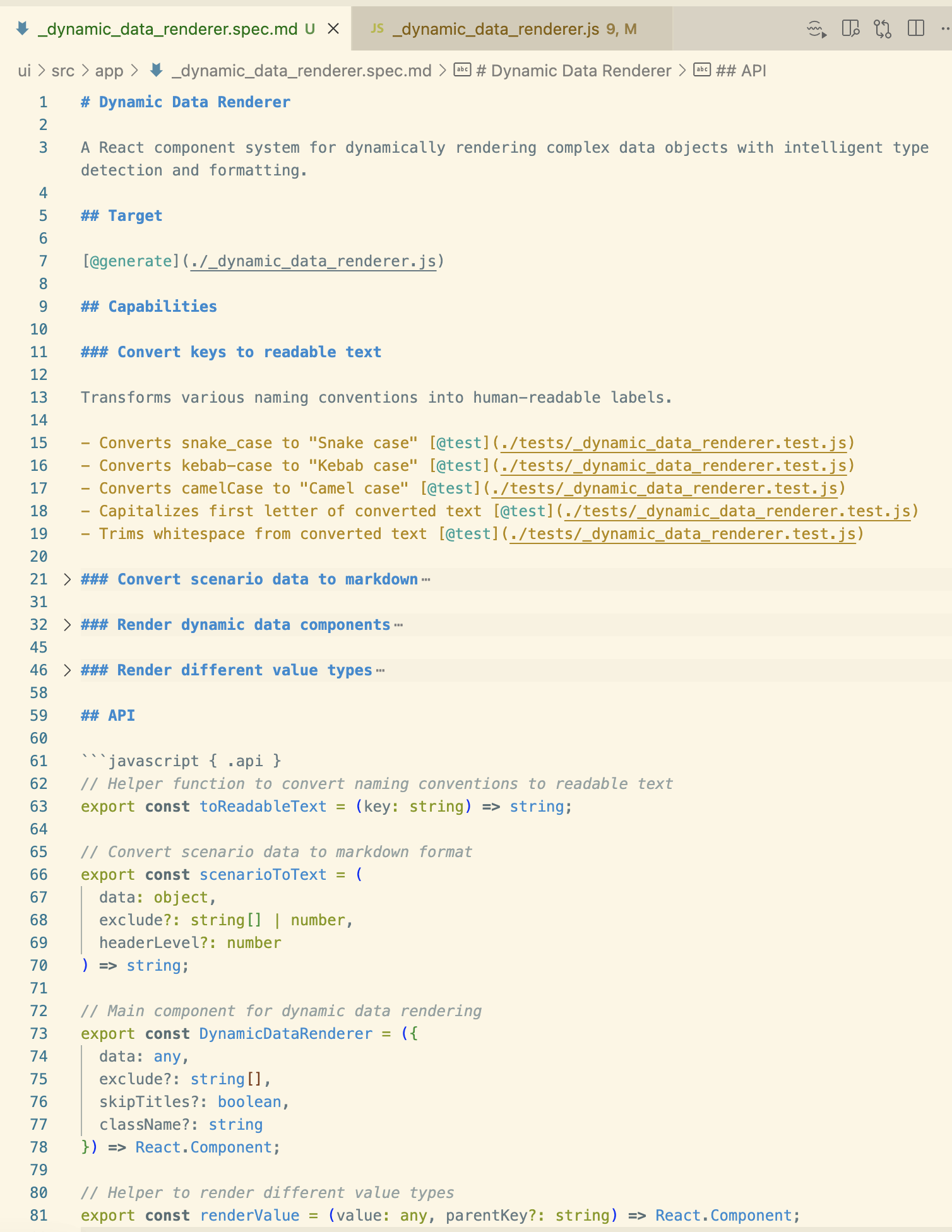
Tags อย่าง @generate หรือ @test ดูเหมือนจะบอก Tessl ว่าควรสร้างอะไร ส่วน API section แสดงแนวคิดของการกำหนด interfaces ที่ถูกเปิดเผยไปยังส่วนอื่นๆ ของ codebase ไว้ใน spec เพื่อให้แน่ใจว่าส่วนที่สำคัญกว่าของ component ที่ถูกสร้างขึ้นนั้นอยู่ภายใต้การควบคุมของผู้ดูแลอย่างสมบูรณ์ การรัน tessl build สำหรับ spec นี้จะสร้างไฟล์ JavaScript code ที่สอดคล้องกัน
การวาง spec สำหรับ spec-as-source ไว้ที่ระดับ abstraction ที่ค่อนข้างต่ำ ต่อ code file หนึ่งไฟล์ อาจช่วยลดจำนวนขั้นตอนและการตีความที่ LLM ต้องทำ และลดโอกาสของ error อย่างไรก็ตาม แม้ในระดับ abstraction ที่ต่ำนี้ ผมก็ยังเห็น non-determinism เกิดขึ้น เมื่อผมสร้างโค้ดหลายครั้งจาก spec เดียวกัน มันเป็นการทดลองที่น่าสนใจในการทำซ้ำบน spec และทำให้มันเฉพาะเจาะจงมากขึ้นเรื่อยๆ เพื่อเพิ่มความสามารถในการทำซ้ำได้ของการสร้างโค้ด กระบวนการนั้นทำให้ผมนึกถึง pitfalls และความท้าทายบางอย่างของการเขียน specification ที่ไม่คลุมเครือและสมบูรณ์
Observations and questions (ข้อสังเกตและคำถาม)
เครื่องมือทั้งสามตัวนี้ต่างก็เรียกตัวเองว่าการนำ spec-driven development มาใช้ แต่มันก็แตกต่างกันมาก ดังนั้นนี่คือสิ่งแรกที่ต้องจำไว้เมื่อพูดถึง SDD มันไม่ได้มีแค่รูปแบบเดียว
One workflow to fit all sizes? (Workflow เดียวสำหรับทุกขนาด?)
Kiro และ spec-kit ต่างก็มี workflow ที่ชัดเจนของตัวเอง แต่ผมค่อนข้างแน่ใจว่าไม่มีเครื่องมือไหนที่เหมาะกับปัญหาการเขียนโค้ดในชีวิตจริงส่วนใหญ่ โดยเฉพาะอย่างยิ่ง มันยังไม่ค่อยชัดเจนสำหรับผมว่าพวกมันจะรองรับปัญหาที่มีขนาดแตกต่างกันมากพอที่จะสามารถใช้งานได้ทั่วไปหรือไม่
เมื่อผมขอให้ Kiro แก้บั๊กเล็กๆ (มันเป็นบั๊กเดียวกับที่ผมเคยใช้ลอง Codex มาก่อน) มันก็ชัดเจนอย่างรวดเร็วว่า workflow นี้เหมือนการใช้ค้อนขนาดใหญ่ตอกตะปู เอกสาร requirements เปลี่ยนบั๊กเล็กๆ นี้เป็น 4 "user stories" ที่มี acceptance criteria รวม 16 ข้อ รวมถึงอัญมณีอย่าง "User story: ในฐานะนักพัฒนา ผมต้องการให้ฟังก์ชันการแปลงจัดการกับ edge cases อย่างงดงาม เพื่อให้ระบบยังคงแข็งแกร่งเมื่อมีรูปแบบหมวดหมู่ใหม่ๆ ถูกนำเข้ามา"
ผมมีความท้าทายคล้ายๆ กันเมื่อใช้ spec-kit ผมไม่แน่ใจว่าควรใช้มันกับปัญหาขนาดไหน บทเรียนที่มีอยู่มักจะเกี่ยวกับการสร้างแอปพลิเคชันจากศูนย์ เพราะนั่นเป็นวิธีที่ง่ายที่สุดสำหรับบทเรียน หนึ่งใน use cases ที่ผมลองคือ feature ที่จะเป็นเรื่องราวขนาด 3-5 คะแนนในทีมเก่าของผม feature นี้ขึ้นอยู่กับโค้ดที่มีอยู่แล้วจำนวนมาก มันถูกออกแบบมาเพื่อสร้าง modal ภาพรวมที่สรุปข้อมูลจำนวนหนึ่งจาก dashboard ที่มีอยู่ ด้วยจำนวนขั้นตอนที่ spec-kit ใช้ และจำนวน markdown files ที่มันสร้างให้ผมตรวจสอบ มันก็รู้สึกเกินความจำเป็นอีกแล้วสำหรับขนาดของปัญหา มันเป็นปัญหาที่ใหญ่กว่าที่ผมใช้กับ Kiro แต่ก็มี workflow ที่ซับซ้อนกว่ามากเช่นกัน ผมไม่เคยทำการ implement จนเสร็จ แต่ผมคิดว่าในเวลาเดียวกันที่ผมใช้ในการรันและตรวจสอบผลลัพธ์ของ spec-kit ผมน่าจะ implement feature นั้นด้วยการเขียนโค้ดแบบ "ธรรมดา" ด้วยความช่วยเหลือของ AI และคงรู้สึกว่าควบคุมได้มากกว่า
SDD tool ที่มีประสิทธิภาพอย่างน้อยที่สุดก็ต้องมีความยืดหยุ่นสำหรับ workflow หลักที่แตกต่างกันสองสามแบบ สำหรับการเปลี่ยนแปลงที่มีขนาดและประเภทต่างกัน
Reviewing markdown over reviewing code? (ตรวจสอบ markdown แทนที่จะตรวจสอบโค้ด?)
ดังที่ได้กล่าวไปแล้ว และอย่างที่คุณเห็นในคำอธิบายของเครื่องมือข้างต้น spec-kit สร้าง markdown files จำนวนมากให้ผมตรวจสอบ พวกมันซ้ำซ้อน ทั้งซึ่งกันและกัน และกับโค้ดที่มีอยู่แล้ว บางไฟล์ก็มีโค้ดอยู่แล้วด้วย โดยรวมแล้วพวกมัน verbose มากและน่าเบื่อในการตรวจสอบ สำหรับ Kiro มันง่ายกว่าเล็กน้อย เพราะคุณได้แค่ 3 ไฟล์ และมันเข้าใจง่ายกว่าด้วยโมเดลความคิดแบบ "requirements > design > tasks" อย่างไรก็ตาม อย่างที่กล่าวไป Kiro ก็ verbose เกินไปสำหรับบั๊กเล็กๆ ที่ผมขอให้มันแก้เช่นกัน
พูดกันตามตรง ผมอยากตรวจสอบโค้ดมากกว่าไฟล์ markdown เหล่านี้ทั้งหมด SDD tool ที่มีประสิทธิภาพจะต้องมอบประสบการณ์การตรวจสอบ spec ที่ดีมากๆ
False sense of control? (ความรู้สึกว่าควบคุมได้แบบลวงตา?)
ถึงแม้จะมีไฟล์ templates prompts workflows และ checklists มากมายขนาดนี้ ผมก็ยังเห็น agent ไม่ทำตามคำแนะนำทั้งหมดบ่อยครั้ง ใช่แล้ว ตอนนี้ context windows ใหญ่ขึ้น ซึ่งมักถูกกล่าวถึงว่าเป็นหนึ่งในตัวขับเคลื่อนของ spec-driven development แต่แค่ windows ใหญ่ขึ้น ไม่ได้หมายความว่า AI จะรับรู้ทุกอย่างที่อยู่ในนั้นได้อย่างถูกต้อง
ตัวอย่างเช่น: Spec-kit มีขั้นตอนการวิจัยระหว่างการวางแผน และมันค้นคว้าเกี่ยวกับโค้ดที่มีอยู่แล้วได้ดีมาก ซึ่งเยี่ยมมากเพราะผมขอให้มันเพิ่ม feature ที่ต่อยอดจากโค้ดที่มีอยู่ แต่สุดท้าย agent ก็ไม่สนใจโน้ตที่ว่านี่คือคำอธิบายของคลาสที่มีอยู่แล้ว มันกลับถือว่าเป็น specification ใหม่และสร้างมันขึ้นมาทั้งหมดอีกครั้ง ทำให้เกิด duplicates แต่ผมไม่เพียงแค่เห็นตัวอย่างของการไม่สนใจคำสั่งเท่านั้น ผมยังเห็น agent ทำมากเกินไปเพราะมันตั้งใจทำตามคำสั่งมากเกินไป (เช่น หนึ่งใน constitution articles)
อดีตได้แสดงให้เห็นแล้วว่าวิธีที่ดีที่สุดสำหรับเราในการรักษาการควบคุมสิ่งที่เรากำลังสร้างคือการทำขั้นตอนเล็กๆ แบบ iterative ดังนั้นผมจึงค่อนข้างไม่เชื่อว่าการออกแบบ spec จำนวนมากไว้ล่วงหน้าเป็นความคิดที่ดี โดยเฉพาะอย่างยิ่งเมื่อมัน verbose เกินไป SDD tool ที่มีประสิทธิภาพจะต้องรองรับแนวทางแบบ iterative แต่ package งานเล็กๆ ดูเหมือนจะขัดกับแนวคิดของ SDD
How to effectively separate functional from technical spec? (จะแยก functional spec ออกจาก technical spec อย่างมีประสิทธิภาพได้อย่างไร?)
เป็นความคิดที่แพร่หลายใน SDD ที่จะตั้งใจแยกความแตกต่างระหว่าง functional spec และ technical implementation ความปรารถนาพื้นฐานก็คือ ท้ายที่สุดแล้ว เราอาจให้ AI กรอกรายละเอียดและแนวทางการแก้ปัญหาทั้งหมด และสามารถเปลี่ยนไปใช้ tech stack ที่แตกต่างกันด้วย spec เดียวกัน
ในความเป็นจริง เมื่อผมลอง spec-kit ผมสับสนบ่อยครั้งว่าควรอยู่ในระดับ functional เมื่อไหร่ และเมื่อไหร่ควรเพิ่มรายละเอียดทางเทคนิค บทเรียนและ documentation ก็ไม่ค่อยสอดคล้องกันในเรื่องนี้ ดูเหมือนจะมีการตีความที่แตกต่างกันว่า "purely functional" แท้จริงแล้วหมายถึงอะไร และเมื่อผมนึกย้อนกลับไปถึง user stories มากมายที่ผมอ่านในอาชีพการงานของผมที่ไม่ได้แยก requirements ออกจาก implementation อย่างถูกต้อง ผมไม่คิดว่าเรามีประวัติที่ดีในฐานะวิชาชีพในการทำสิ่งนี้ได้ดี
Who is the target user? (ใครคือผู้ใช้เป้าหมาย?)
หลายๆ demo และบทเรียนสำหรับ spec-driven development tools รวมถึงสิ่งต่างๆ เช่น การกำหนดเป้าหมายของ product และ feature พวกเขายังรวมคำศัพท์อย่าง "user story" ด้วย แนวคิดที่นี่อาจเป็นการใช้ AI เป็นตัวขับเคลื่อนสำหรับ cross-skilling และให้ developers มีส่วนร่วมในการวิเคราะห์ requirements มากขึ้น? หรือให้ developers จับคู่กับ product people เมื่อพวกเขาทำงานใน workflow นี้? ไม่มีสิ่งใดถูกทำให้ชัดเจนเลย มันถูกนำเสนอเป็นเรื่องปกติว่านักพัฒนาจะต้องวิเคราะห์ทั้งหมดนี้
ในกรณีนั้น ผมก็จะถามตัวเองอีกครั้งว่า SDD มีไว้สำหรับปัญหาและขนาดไหน? น่าจะไม่ใช่สำหรับ features ขนาดใหญ่ที่ยังคลุมเครือมาก เพราะแน่นอนว่ามันต้องใช้ทักษะด้าน product และ requirements ที่เชี่ยวชาญกว่า และขั้นตอนอื่นๆ อีกมากมาย เช่น การวิจัยและการมีส่วนร่วมของผู้มีส่วนได้ส่วนเสีย?
Spec-anchored and spec-as-source: Are we learning from the past? (Spec-anchored และ spec-as-source: เราเรียนรู้จากอดีตหรือเปล่า?)
ในขณะที่หลายคนเปรียบเทียบ SDD กับ TDD หรือ BDD ผมคิดว่าอีกสิ่งที่สำคัญที่ต้องพิจารณา โดยเฉพาะสำหรับ spec-as-source คือ MDD (model-driven development) ผมทำงานในสองสามโปรเจกต์ตอนต้นอาชีพที่ใช้ MDD อย่างหนัก และผมนึกถึงมันตลอดเวลาตอนที่ลองใช้ Tessl Framework models ใน MDD ก็คือ specs นั่นเอง แม้ว่าจะไม่ใช่ภาษาธรรมชาติ แต่แสดงออกผ่านเช่น custom UML หรือ textual DSL เราสร้าง custom code generators เพื่อเปลี่ยน specs เหล่านั้นเป็นโค้ด

ท้ายที่สุดแล้ว MDD ไม่เคยได้รับการยอมรับในวงกว้างสำหรับแอปพลิเคชันทางธุรกิจ มันอยู่ในระดับ abstraction ที่อึดอัดและสร้าง overhead และข้อจำกัดมากเกินไป แต่ LLMs ช่วยขจัด overhead และข้อจำกัดบางอย่างของ MDD ออกไป ดังนั้นจึงมีความหวังใหม่ว่าตอนนี้เราสามารถโฟกัสที่การเขียน specs และสร้างโค้ดจากมันได้แล้ว ด้วย LLMs เราไม่ได้ถูกจำกัดด้วยภาษา spec ที่กำหนดไว้ล่วงหน้าและ parseable ได้อีกต่อไป และเราไม่ต้องสร้าง code generators ที่ซับซ้อนอีกแล้ว ราคาที่ต้องจ่ายสำหรับสิ่งนั้นก็คือ non-determinism ของ LLMs แน่นอน และโครงสร้างที่ parseable ได้ก็มีข้อดีที่เรากำลังเสียไปเช่นกัน: เราสามารถให้การสนับสนุนเครื่องมือมากมายแก่ผู้เขียน spec ในการเขียน spec ที่ถูกต้อง สมบูรณ์ และสอดคล้องกัน ผมสงสัยว่า spec-as-source และแม้แต่ spec-anchoring อาจจะจบลงด้วยข้อเสียของทั้ง MDD และ LLMs: ความไม่ยืดหยุ่น และ non-determinism
เพื่อให้ชัดเจน ผมไม่ได้คิดถึงประสบการณ์ MDD ในอดีตและบอกว่า "เราก็น่าจะเอาสิ่งนั้นกลับมา" แต่เราควรมองไปที่ความพยายามในการสร้างโค้ดจาก spec ในอดีตเพื่อเรียนรู้จากมันเมื่อเราสำรวจ spec-driven ในปัจจุบัน
Conclusions (บทสรุป)
ในการใช้งาน AI-assisted coding ส่วนตัวของผม ผมมักจะใช้เวลากับการสร้าง spec ในรูปแบบใดรูปแบบหนึ่งอย่างพิถีพิถันก่อนที่จะให้ agent เขียนโค้ด ดังนั้นหลักการทั่วไปของ spec-first จึงมีคุณค่าอย่างแน่นอนในหลายสถานการณ์ และแนวทางต่างๆ ในการจัดโครงสร้าง spec นั้นเป็นที่ต้องการอย่างมาก สิ่งเหล่านี้เป็นหนึ่งในคำถามที่พบบ่อยที่สุดที่ผมได้ยินจากผู้ปฏิบัติงานในตอนนี้: "ฉันจะจัดโครงสร้าง memory bank ยังไงดี?", "ฉันจะเขียน specification และ design document ที่ดีสำหรับ AI ได้อย่างไร?"
แต่คำว่า "spec-driven development" ยังไม่ได้ถูกนิยามไว้ดีนัก และมันก็เริ่มเกิด semantic diffusion ขึ้นแล้ว ผมเพิ่งได้ยินคนใช้คำว่า "spec" เป็นคำพ้องความหมายของ "detailed prompt" ด้วยซ้ำ
ในส่วนของเครื่องมือที่ผมได้ลอง ผมได้ระบุคำถามมากมายเกี่ยวกับประโยชน์ในโลกจริงของพวกมันไว้ที่นี่ ผมสงสัยว่าบางตัวกำลังพยายามป้อน workflow ที่มีอยู่ของเราให้กับ AI agents อย่างตรงตัวเกินไปหรือเปล่า ซึ่งท้ายที่สุดแล้วก็ขยายความท้าทายที่มีอยู่แล้วอย่าง review overload และ hallucinations โดยเฉพาะอย่างยิ่งกับแนวทางที่ซับซ้อนกว่าที่สร้างไฟล์จำนวนมาก ผมอดคิดถึงคำประสมภาษาเยอรมัน "Verschlimmbesserung" ไม่ได้: เรากำลังทำให้บางอย่างแย่ลงในความพยายามที่จะทำให้ดีขึ้นหรือเปล่า?