
GitHub Copilot Proxy: พลังเบื้องหลังการทำ Code Completion ระดับพระกาฬ
GitHub Copilot คืออะไร?
GitHub เป็น social coding platform ที่ใหญ่ที่สุดในโลก มีผู้ใช้งานมากกว่า 100 ล้านคน เขาเรียกมันว่า “บ้านของนักพัฒนาทุกคน”
ส่วน GitHub Copilot ที่ผมจะพูดถึงวันนี้ จะโฟกัสที่ฟีเจอร์ code completion ซึ่งเป็นส่วนที่ผมทำงานอยู่ จริงๆ แล้ว Copilot มีหลายฟีเจอร์ เช่น chat, interactive refactoring และอื่นๆ แต่โดยรวมพวกมันใช้สถาปัตยกรรมคล้ายกัน ต่างกันแค่รายละเอียดนิดหน่อย
Copilot ใช้ได้ผ่าน extension ที่ติดตั้งลงใน IDE ปัจจุบันรองรับ IDE หลักๆ เช่น
- VS Code
- Visual Studio
- กลุ่ม IntelliJ ทั้งหลาย
- NeoVim
- และล่าสุดทาง Github ประกาศรองรับ Xcode แล้วด้วย
เรียกได้ว่า “อยากใช้ Copilot ใน IDE ไหน ก็แทบจะหาได้หมด”
เรารองรับ มากกว่า 400 ล้าน completion requests ตอนที่เสนอหัวข้อนี้ และตัวเลขก็เพิ่มขึ้นเรื่อยๆ ปัจจุบัน peak ที่ 8,000 requests ต่อวินาที ช่วงบ่ายของยุโรปต่อเนื่องไปยังเวลาทำงานของสหรัฐฯ
ในช่วง peak นั้น response time เฉลี่ยก็ยังต่ำกว่า 200ms
GitHub Copilot ทำงานอย่างไรใน IDE?
ถ้ายังไม่เคยเห็น Copilot ทำงาน นี่คือสิ่งที่คุณจะได้เห็น:
เวลาคุณพิมพ์โค้ด Copilot จะ “เดา” และเสนอ code snippets อัตโนมัติ (ghost text) ที่เป็นสีเทาใน IDE ทุกครั้งที่หยุดพิมพ์หรือชะงักนิดๆ มันจะเริ่มเดาคำสั่งถัดไปทันที
เช่น คุณอาจพิมพ์ comment อธิบายว่าอยากให้เขียน function แบบไหน Copilot จะพยายาม generate function ให้คุณทันที โดยมันจะเรียนรู้ “pattern” จากสิ่งที่คุณกำลังทำอยู่
แนวคิดคือ “interactive code completion” ต้อง ทำงานได้เร็วกว่า autocomplete แบบในเครื่อง เช่น LSP, IntelliSense หรือ Code Sense ต่างๆ เพราะพวกนั้นทำงาน local ไม่ต้องส่งข้อมูลผ่าน network เลย
แต่ Copilot ต้องส่ง request ข้าม network, แชร์ resource, รับมือกับ cloud outage ด้วย มันจึงมี “มาตรฐานสูง” ที่ต้องทำให้ได้เท่า หรือเหนือกว่า autocomplete ธรรมดาใน IDE
ข้อกำหนดและความท้าทายในการสร้าง GitHub Copilot Proxy
เป้าหมายคือการทำ interactive code completion ภายใน IDE แบบ real-time ซึ่งต้อง “แข่งขัน” โดยตรงกับ autocomplete ในตัว IDE เช่น LSP-powered autocomplete, Code Sense หรือ IntelliSense
และแน่นอนว่าพวก autocomplete ในเครื่อง ไม่ต้องรับมือกับปัญหา network latency, server resource sharing หรือ cloud outage แบบที่ทีม Github copilot ต้องเจอ ดังนั้นมาตรฐานที่ทีมต้องทำให้ได้ถือว่าสูงมาก
เพื่อให้ Copilot สามารถแข่งขันได้ เราต้องทำ 3 สิ่งหลักๆ:
- ลด latency ทั้งก่อนและระหว่างการส่ง request
- Amortize หรือเฉลี่ย cost ของการตั้งค่า connection เพราะนี่เป็น network service ไม่ใช่ local
- หลีกเลี่ยง network latency ให้ได้มากที่สุด เพราะ overhead ตรงนี้คือข้อเสียเปรียบใหญ่ที่ autocomplete ในเครื่องไม่ต้องเจอ
อีกจุดหนึ่งที่สำคัญมากคือ
ความยาวของ request มีผลโดยตรงกับเวลาที่ใช้ในการตอบกลับ
ดังนั้นจึงเลือกทำระบบให้ทำงานแบบ streaming คือเริ่มส่งข้อมูลกลับทันทีตั้งแต่ได้ผลลัพธ์ชุดแรก โดยไม่ต้องรอให้ request เสร็จสมบูรณ์ก่อน คอนเซ็ปต์นี้สำคัญมาก และช่วยให้ unlock optimization อื่นๆ ได้อีกเยอะ
การตั้งค่า Connection เป็นเรื่อง แพง
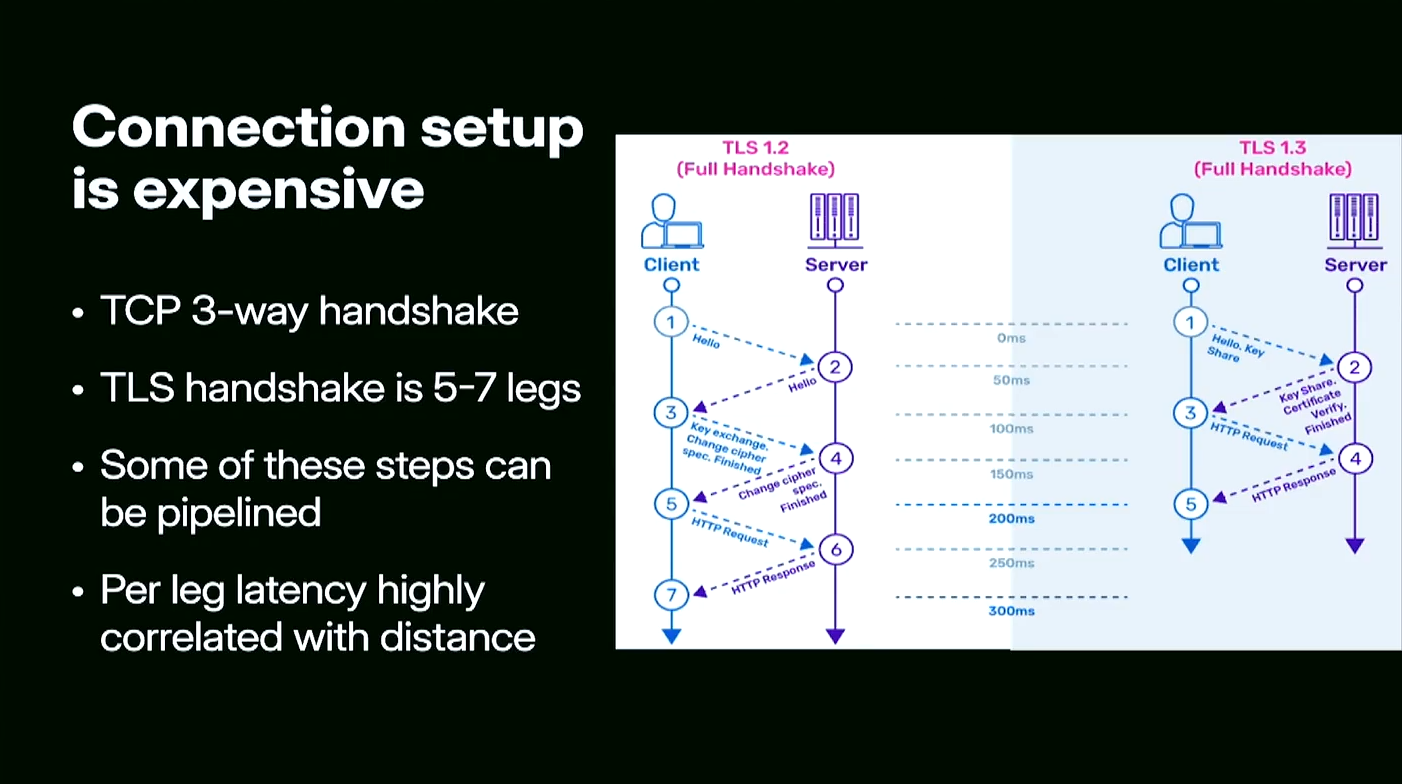
เนื่องจากนี่เป็น network service การตั้งค่า connection ทุกครั้งผ่าน TCP จะต้องทำ TCP three-way handshake (SYN, SYN-ACK, ACK) และเพื่อความปลอดภัยก็ต้องครอบด้วย TLS ซึ่งเพิ่มการทำ handshake อีก 5–7 ขั้นตอนเข้าไปอีก
แม้ว่าจะมีการ optimize พวก TLS Fast Start หรือ Zero Round Trip (0-RTT) แล้วก็ตาม แต่มันยังคงมีต้นทุนอยู่ ไม่สามารถลดค่าใช้จ่าย network ให้เป็นศูนย์ได้จริง
การตั้งค่า connection หนึ่งครั้งโดยทั่วไปใช้ 5–6 รอบ การส่งข้อมูลไปกลับ (round trip)
ซึ่งเวลาของแต่ละรอบสัมพันธ์กับ ระยะทาง อย่างมาก ตัวอย่างเช่น
- อเมริกาฝั่งตะวันออกไปตะวันตกประมาณ 50ms ต่อรอบ
- ถ้าอยู่ข้ามมหาสมุทร (อย่างยุโรปไปอเมริกา หรือเอเชียไปอเมริกา) จะเห็น round trip time สูงกว่า 100ms ได้ไม่ยาก
คูณเข้าไป 5–6 รอบ กลายเป็น connection setup ครั้งหนึ่งกินเวลาเป็น หลายร้อย milliseconds ทันที นี่คือ “ศัตรูหมายเลขหนึ่ง” ในการทำให้ Copilot ตอบสนองได้เร็ว
ทางออกคือ: ตั้ง connection ครั้งเดียว แล้ว “เก็บ” ไว้ให้นานที่สุด
ย้อนดูวิวัฒนาการของ GitHub Copilot
ยุคแรกเริ่มของ Copilot:
ตอนยังเป็น alpha version ผู้ใช้ต้องไปสมัคร OpenAI account, ขอ API key แล้วค่อยเอา key นั้นมากรอกใน IDE เพื่อใช้งาน Copilot
ซึ่งวิธีนี้ ทำงานได้ดีในช่วงแรกๆ กับผู้ใช้แค่ “หลักสิบ” คน แต่ปัญหาคือ:
- OpenAI ไม่อยากทำ user management
- GitHub เองก็ไม่อยากรู้ข้อมูลส่วนตัวของผู้ใช้
- เราต้องการแค่ให้ Copilot เป็น service provider ที่ส่งการบริการผ่าน key เฉยๆ โดยไม่ยุ่งกับ identity
ปัญหา:
การฝัง API key ลงไปใน extension ยังไง ก็ไม่สามารถซ่อนมันจาก hacker ได้ เพราะ security by obscurity เป็นแนวทางที่ “ผิด” ตั้งแต่แรก (ถามบริษัท Rabbit R1 ได้เลย)
การสร้าง Copilot Proxy: ตัวกลางแห่งการพิสูจน์ตัวตน
ทางออกคือการสร้าง proxy ขึ้นมาคั่นกลาง ระหว่าง IDE กับ model จริงๆ
Copilot Proxy ทำหน้าที่อะไร?
- รับ request จาก IDE
- ตรวจสอบ “short-lived token” ที่ IDE แนบมาด้วย
- ถ้า token ถูกต้อง (signature valid) ก็สลับใส่ “real API key” และส่งต่อไปยัง LLM
- แล้ว stream คำตอบกลับให้ IDE
โดยตัว token จะมีอายุแค่ไม่กี่นาที (10–30 นาที) เพื่อ:
- ลดความเสียหายถ้า token ถูกขโมย
- ให้สามารถ revoke การออก token ได้เร็วกรณี user ถูก abuse
Client (IDE) จะรู้ว่า token หมดอายุเมื่อไหร่ และจะเริ่มกระบวนการขอ token ใหม่อัตโนมัติ 2–3 นาทีก่อนหมดอายุ โดยผู้ใช้ไม่ต้องทำอะไรเลย
ข้อดีของระบบนี้:
- ไม่ต้องทำ external auth check ทุกครั้ง
- ลด latency มหาศาล
- Client ยังคิดว่าตัวเองคุยกับ model โดยตรง
แล้ว Copilot จะรู้ได้ยังไงว่า "ควรเริ่มเติมโค้ดตอนไหน"?
Copilot ไม่มี “ปุ่ม autocomplete” แบบสมัยก่อน (เช่น Ctrl+Space ใน Eclipse) แต่จะทำงานแบบ auto โดยดูจากพฤติกรรมการพิมพ์ของผู้ใช้แทน
คำถามสำคัญคือ “เมื่อไหร่ควรสลับจาก user typing ไปเป็น copilot typing?”
แนวทางที่เป็นไปได้เช่น:
- ตั้ง timer ไว้หลังการกด key ทุกครั้ง ถ้า timer หมดโดยไม่มีการพิมพ์เพิ่ม = trigger completion
- ใช้ tiny ML model ทำนายว่าผู้ใช้ “กำลังจะพิมพ์จบ” หรือยัง
- หรือเดาแบบสุดโต่งเลยว่า “พอกด key ครั้งล่าสุด ก็ถือว่าจบแล้ว” ทันที
ในความจริง เราใช้วิธี “ผสมทุกแนวทาง” แล้วปรับ fine-tune ตามพฤติกรรมจริง
อย่างไรก็ตาม
ถึงจะทุ่ม effort ขนาดไหน 50% ของ requests ยังคงเป็น type-through
คือระหว่างที่ Copilot ขอ completion ไปแล้ว ผู้ใช้ก็ดันพิมพ์ต่อ ทำให้คำตอบที่รออยู่นั้น “หมดความหมาย” ทันที
ถ้าอยากลด type-through ก็ต้อง “รอ” ให้แน่ใจว่าผู้ใช้หยุดพิมพ์แล้วจริงๆ ก่อนค่อยส่ง request
แต่การรอก็ทำให้ทุกอย่างช้าลงอีก
ดังนั้นทางแก้คือ:
สร้างระบบ cancel request ทันทีถ้า user พิมพ์ต่อ
(และนี่จะนำไปสู่เรื่อง HTTP request cancellation ที่น่าสนใจมากในตอนต่อไป)
Cancel Request ไม่ได้ง่ายอย่างที่คิด
เวลาใช้ web browser แล้วกดปุ่ม Stop เพื่อหยุดโหลดหน้าเว็บ หรือปิดแท็บไปเลย นั่นแหละคือการ “cancel” request
เบื้องหลังการทำงานมันจะส่ง TCP Reset เพื่อตัดการเชื่อมต่อทันที
แต่ในฝั่ง Server (backend application หรือ web framework)
Server จะ “ไม่รู้ตัว” ว่าผู้ใช้กดยกเลิก จนกระทั่ง:
- กำลัง อ่าน request body
- หรือ เขียน response กลับไป
และปัญหาใหญ่สำหรับ LLM inference คือ
ขั้นตอนที่แพงที่สุด (หนักที่สุด) คือการ “ทำ inference” เพื่อสร้าง token แรก ซึ่งมันเกิดขึ้น ก่อนที่จะเริ่มส่งข้อมูลกลับ ด้วยซ้ำ
ดังนั้นสถานการณ์ที่เกิดขึ้นจริงคือ:
- Copilot รับ request จากผู้ใช้
- เริ่มทำ inference ใน LLM (ค่าใช้จ่ายแพงมาก)
- ยังไม่ได้ส่งอะไรกลับไปเลย
- รู้ตัวอีกที ผู้ใช้พิมพ์ต่อแล้ว Request “Cancel” ไปแล้ว
- งาน inference ทั้งหมดที่ทำมา “ต้องทิ้งลงพื้น” (waste CPU, waste memory, waste energy)
ใน Copilot นี่คือเหตุการณ์ที่เกิดขึ้น 40–45% ของเวลาทั้งหมด 😱
พูดง่ายๆ คือ ครึ่งหนึ่งของงานที่ทำมาทั้งหมด เสียไปโดยเปล่าประโยชน์
ปัญหาอีกขั้น: การ Cancel ใน HTTP/1
ใน HTTP/1.1 model หนึ่ง connection รองรับได้แค่ หนึ่ง request เท่านั้น
ถ้าอยาก cancel request ใน HTTP/1.1 ต้อง reset TCP connection ไปเลย ซึ่ง:
- ต้องเสียเวลาสร้าง TCP/TLS connection ใหม่ (จำได้ไหมว่าต้อง 5–6 round trips)
- แพงมาก เสียเวลาเป็นร้อย ms
ใน worst case ถ้าผู้ใช้พิมพ์เร็วมาก cancel บ่อยมาก = ทุกๆ request จะต้อง “สร้าง connection ใหม่” ซึ่ง latency รวมๆ แย่กว่า แค่ปล่อยให้ request เก่ารันจนจบซะอีก
HTTP/2 คือพระเอกที่มาแก้ปัญหานี้

ใน HTTP/2 และ HTTP/3 (และ QUIC) โลกเปลี่ยนไป:
- มีแค่ หนึ่ง TCP/TLS connection
- แต่สามารถ multiplex หลาย request ผ่าน connection นั้นได้
- แต่ละ request เรียกว่า stream
เวลา Cancel Request ใน HTTP/2:
- ไม่ต้องปิดทั้ง connection
- แค่ “reset” stream เฉพาะอันนั้น แล้วเริ่ม request ใหม่บน stream ใหม่
- TCP connection หลักยังเปิดอยู่ ไม่ต้องรื้อ handshake ใหม่
ในระบบ Copilot:
- IDE ใช้ HTTP/2 เชื่อมกับ Copilot Proxy
- Proxy ใช้ HTTP/2 เชื่อมต่อกับ Model Server บน Azure ด้วยเหมือนกัน
- เรามี connection pooling ที่ Proxy เพื่อ fan-in request จำนวนมากไปยัง model แบบกระจาย load
ข้อดี:
- Connection จะ “อุ่น” อยู่ตลอดเวลา
- TCP congestion window โตขึ้นเรื่อยๆ ไว้ใจได้ ส่ง data ได้เยอะขึ้น
- ลด Latency ได้มหาศาล เพราะไม่ต้องทำ TLS handshake ซ้ำๆ
แล้ว Copilot Proxy ใช้ภาษาอะไร?
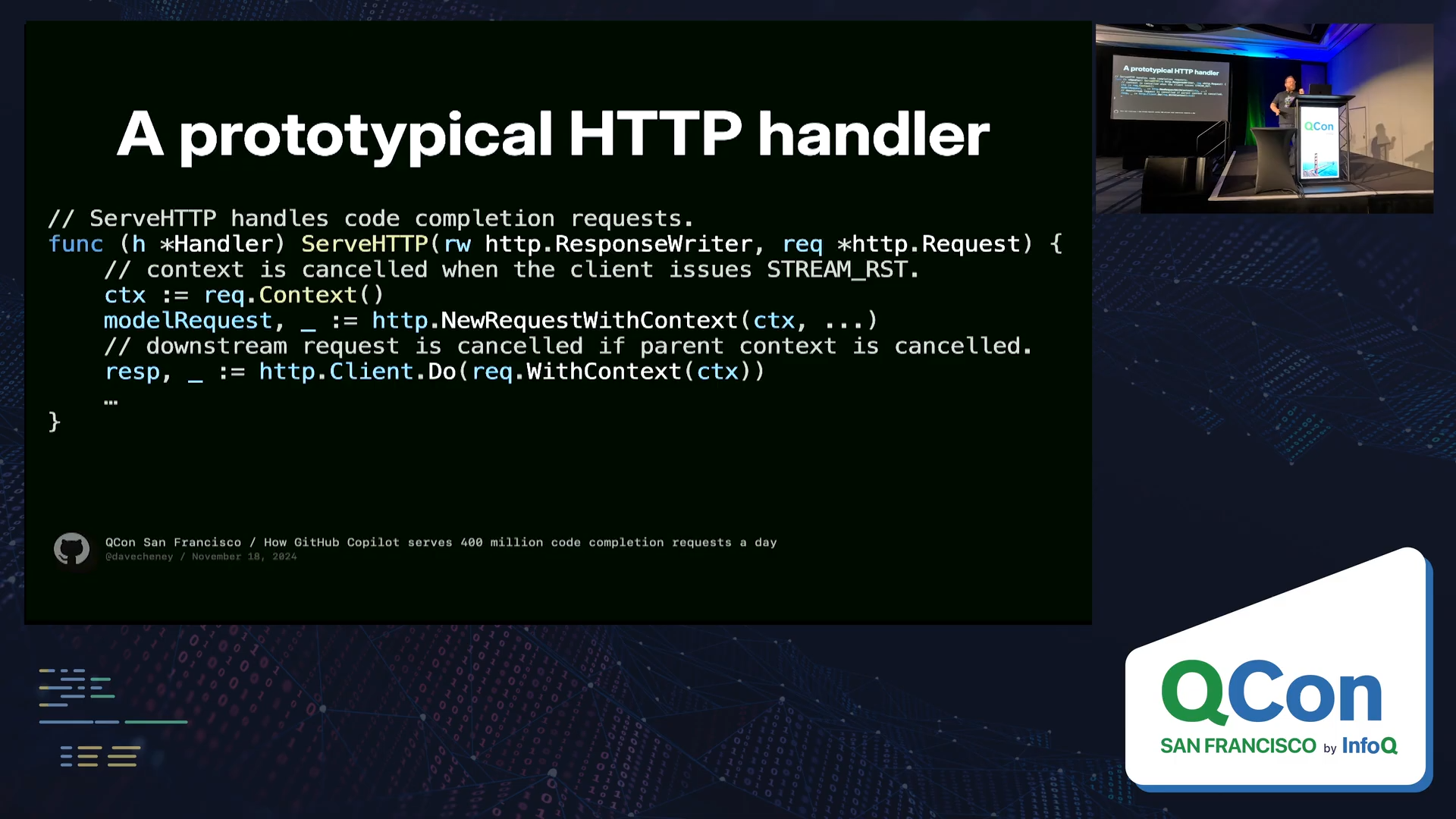
Copilot Proxy เขียนด้วย Go (Golang)
เพราะ Go มี HTTP/2 support ในมาตรฐานที่ดีมาก พร้อมทั้งมีการจัดการ context.Context ที่ใช้สำหรับ:
- ทำ timeout
- ทำ cancellation
- ทำ deadline propagation
ตัว Request.Context() ของ Go เชื่อมโยงตรงกับสถานะของการเชื่อมต่อจริงๆ
เวลา user cancel ผ่าน IDE →
- IDE reset HTTP/2 stream
- Go HTTP server จะทันที detect ได้ผ่าน context cancellation
- context cancellation จะ propagate ทะลุไปถึง Model API call ได้เลย
- ทั้งหมดนี้เกิดแบบทันที ไม่ต้องรอเขียน/อ่าน network อีก
พูดง่ายๆ คือ “กดยกเลิกจากฝั่ง IDE แล้วทุกอย่าง cancel ได้ทันที”
ปัญหาใหม่: ไม่ใช่ทุก Load Balancer รองรับ HTTP/2 ตรง backend!
ถึงแม้ HTTP/2 จะออกมาตั้งแต่ 2015
แต่ Load Balancer ส่วนใหญ่:
- รองรับ HTTP/2 เฉพาะ “frontend” ระหว่าง client → LB
- แต่ “backend” LB → service ยัง downgrade เป็น HTTP/1 อยู่ดี 😩
เช่น:
- AWS ALB, NLB
- Cloud CDN ส่วนใหญ่
- รวมถึง OpenAI ใช้ Nginx (ตอนนั้น) ซึ่ง hard-coded limit ไว้ที่ 100 requests ต่อ connection พอครบต้องสร้าง connection ใหม่
นี่ทำให้ GitHub ตัดสินใจ:
ใช้ GitHub Load Balancer (GLB) ของตัวเอง!
- GLB ใช้ HAProxy เป็น core
- HAProxy มี HTTP/2 support ที่ดีที่สุดตัวหนึ่งในโลก open source
- GLB รองรับ HTTP/2 end-to-end จริงๆ
- ควบคุมการจัดการ connection, timeout, keep-alive, reset stream ได้อย่างแม่นยำ
สรุปคือ:
Client → GLB → Copilot Proxy → Model Server ทั้งหมดวิ่งบน HTTP/2 แท้ๆ ตลอดเส้นทาง
Proxy: หัวใจกลางระบบที่ช่วยให้ GitHub Copilot วิ่งได้ไม่สะดุด
ในตอนต้น Copilot Proxy ถูกสร้างขึ้นมาเพื่อแค่ทำหน้าที่ Authenticate ผู้ใช้และสลับ API key ก่อนส่งต่อ request ไปยัง Model Server แต่เมื่อเวลาผ่านไปพบว่าการมี Proxy ชั้นกลางแบบนี้ ให้ประโยชน์มหาศาลเกินกว่าหน้าที่ดั้งเดิมมาก
Proxy ทำให้มี “จุดควบคุมกลาง” ระหว่าง IDE และ Model Server นั่นหมายความว่า เราสามารถมองเห็น request ทุกตัวที่ผ่านไปมา และสามารถทำการแก้ไข ดัดแปลง หรือเพิ่ม logic ใดๆ ก็ตามได้ โดยไม่ต้องไปยุ่งกับฝั่ง Client หรือ Model
ตัวอย่างที่เห็นได้ชัดที่สุด คือปัญหาเรื่อง Latency การวัด Latency จากฝั่ง Client โดยตรงมักได้ตัวเลขที่ปนเปื้อน เพราะผู้ใช้แต่ละคนมีเส้นทางอินเทอร์เน็ตต่างกัน คนที่อยู่หลังดาวเทียมหรือ VPN จะมี Latency สูงกว่าคนที่นั่งอยู่ข้าง Data Center อย่างหลีกเลี่ยงไม่ได้ ถ้าเราเอาค่าเฉลี่ย Latency ของผู้ใช้ทุกคนมาปนกันบน Dashboard สรุปคือเราจะได้ค่าเฉลี่ยที่ไม่สื่ออะไรเลย
ด้วยเหตุนี้ GitHub จึงกำหนดว่า “มุมมองของระบบ” จะอยู่ที่ Proxy Request Latency คือวัดเวลาจากที่ Proxy รับ request จนได้ response กลับมาแทน การใช้จุดวัดที่ Proxy ทำให้มองเห็น Latency จริง ๆ ที่มาจากโครงสร้างพื้นฐานของตัวเองโดยไม่ถูกปนด้วย noise จากอินเทอร์เน็ตของผู้ใช้ และยังสามารถวัดได้แม่นยำว่าปัญหาอยู่ที่ไหน เช่น Model ช้า, Proxy ช้า หรือแค่ network ของผู้ใช้
Proxy ยังเปิดโอกาสให้เราจัดการ Client Versions ได้อย่างมีประสิทธิภาพ ปัญหาที่ทุกคนเจอเหมือนกันคือ “Long Tail of Client Versions” เวลาปล่อย Client ใหม่ออกไป ประมาณ 80% ของผู้ใช้จะอัปเดตภายใน 24–36 ชั่วโมง แต่จะมีอีก 20% ที่เหมือนหายไปในหลุมดำ ใช้เวอร์ชันเก่าอยู่นานจนถึงยุคพลังงานมืดมาครองโลก (เวอร์วังแต่จริง)
การมี Proxy ทำให้สามารถ apply hotfix แบบ server-side ได้ทันที เช่น มีวันหนึ่ง OpenAI แจ้งมาว่า “ห้ามส่ง parameter logprobs เพราะจะทำให้ Model crash” ถ้าต้องไล่แก้ฝั่ง Client อย่างเดียวคงใช้เวลาหลายสัปดาห์ถึงจะ update users ได้หมด แต่ Proxy สามารถดัก parameter อันตรายออกก่อนส่งไปที่ Model ได้ทันที ทำให้การแก้ไขปัญหาแบบฉุกเฉินทำได้เร็วและลดแรงกดดันทั้งสองฝั่งมหาศาล
นอกจาก hotfix แล้ว Proxy ยังเปิดโอกาสให้ทำ Canary Deployments หรือ A/B Testing ได้ง่ายมาก เช่น เวลามี Model เวอร์ชันใหม่ที่อยากทดสอบ แทนที่จะต้องทำงานร่วมกับทีม Client หรือรบกวนผู้ใช้ เราสามารถกำหนดได้ที่ Proxy เลยว่า “5% ของ Traffic จะถูก mirror ไปยัง Model ใหม่แบบ read-only” หรือจะทำ Traffic Split ส่งผู้ใช้บางกลุ่มไป Model A และบางกลุ่มไป Model B เพื่อวัดคุณภาพก็ทำได้ทันทีโดยผู้ใช้ไม่รู้ตัว
อีกตัวอย่างหนึ่งของการใช้ Proxy อย่างคุ้มค่าคือการตรวจจับ “Fast Cancellation Pattern” หลังจากสังเกตว่า มีบาง Request ถูกส่งเข้ามาแล้ว cancel ทันทีภายในเวลา 1 มิลลิวินาที ซึ่งผิดปกติอย่างมากเพราะปกติคนจะพิมพ์เสร็จก่อนค่อย cancel ปรากฏว่ามีบั๊กฝั่ง Client ที่ทำให้ IDE บางเวอร์ชันส่ง Request ออกไปโดยไม่ได้ตั้งใจแล้ว cancel ทันที การมี Proxy ช่วยให้สามารถดักจับการ Cancel เหล่านี้ก่อนจะ forward ไปยัง Model ช่วยประหยัดค่า inference ไปมหาศาล
หากไม่มี Proxy ตรงกลาง เราคงต้องอาศัย metrics จากฝั่ง Model Server ซึ่งมักให้แค่ Request Count กับ Error Rate คร่าวๆ ไม่มี granularity ระดับที่ช่วยให้ dev debug ปัญหาลึกๆ ได้เอง แต่เพราะเราวาง Proxy เป็นตัววัดกลาง ทำให้สามารถสร้าง Observability ระดับ millisecond ได้ด้วยตัวเอง และตรวจสอบ Health Check ของระบบอย่างแม่นยำกว่าการพึ่งข้อมูลจากผู้ให้บริการ upstream อย่างเดียว
เปลี่ยนเหตุการณ์ล่มระบบให้กลายเป็นแค่การแจ้งเตือน: บทบาทของ Proxy ในการยกระดับ Reliability
การที่ GitHub Copilot ต้องให้บริการกับผู้ใช้ทั่วโลก ทำให้การมี Proxy Layer กลางระหว่าง IDE ของผู้ใช้กับ Model Server ไม่ได้แค่ช่วยเรื่องการ optimize request หรือแก้บั๊กเร็วขึ้นเท่านั้น แต่ยังส่งผลโดยตรงต่อความสามารถในการรับมือกับปัญหาระดับ Region หรือการล่มแบบ Partial Outage อีกด้วย
ลองนึกภาพว่า หากเรามีเพียง Model Server ก้อนเดียวอยู่ในอเมริกา แล้วเกิดปัญหาใน Data Center นั้น เช่น ไฟดับ เครือข่ายขัดข้อง หรือปัญหา configuration จน Model ตอบสนองไม่ได้ ผู้ใช้จากทั่วโลกจะได้รับผลกระทบพร้อมกันทันที กลายเป็นเหตุการณ์ Sev-1 หรือ Severity-1 Incident ที่ต้องรีบประกาศเตือนทั่วบริษัท ต้องมีทีมวิ่งแก้ไข และสร้างผลกระทบเชิงชื่อเสียงมหาศาล
แต่เมื่อเปลี่ยนสถาปัตยกรรมไปใช้แนวทาง Multi-Region พร้อมวาง Proxy อยู่ใกล้กับ Model แต่ละก้อน สิ่งที่เกิดขึ้นคือ หาก Region หนึ่งมีปัญหา เช่น Model ที่ยุโรปหยุดทำงาน Proxy ในยุโรปจะหยุดตอบสนอง Health Check ทันที จากนั้น DNS ที่ใช้ OctoDNS จะค่อยๆ หยุดส่ง Traffic มาที่ Proxy นั้นโดยอัตโนมัติ
ผู้ใช้ในยุโรปที่ควรจะถูกส่งไปที่ Proxy ยุโรปก็จะถูก Redirect ไปที่ Region อื่นแทน เช่น อเมริกาหรือเอเชีย แม้ว่าจะมี Latency เพิ่มขึ้นเล็กน้อยจากการเดินทางไกลขึ้น แต่ผู้ใช้จะยังได้รับบริการต่อเนื่อง ไม่มี Error Message โผล่มา ไม่มี Broken Experience เกิดขึ้น จากเดิมที่ต้องประกาศ Sev-1 Incident ว่า “Copilot ใช้ไม่ได้” ตอนนี้กลายเป็นแค่ Alert ภายในทีม DevOps ว่า “Region นี้ไม่พร้อมให้บริการ, กำลัง Redirect Traffic ไป Region อื่นชั่วคราว” เท่านั้น
Proxy ยังทำให้การกระจาย Traffic ไปยังหลาย Model ง่ายขึ้นอย่างเหลือเชื่อ สมมติว่าในยุโรปเรา Deploy Model หลายชุดเพื่อเพิ่ม Capacity Proxy สามารถทำ Load Balancing ได้อัตโนมัติ ส่ง request ไปยัง Model ที่ว่างที่สุดแบบ Real-time และยังสามารถทำ Traffic Shaping ปรับน้ำหนักการกระจาย request ได้ละเอียด เช่น แบ่ง 70% ไป Model A และ 30% ไป Model B เพื่อลดภาระในช่วง Peak Time หรือทำการทดลองเวอร์ชัน Model ใหม่อย่างปลอดภัย
การมี Proxy ช่วยให้เราไม่ต้องพึ่งแค่ Failover ระดับ DNS ซึ่งแม้จะทำงานอัตโนมัติ แต่บางครั้งการเปลี่ยนแปลง DNS Record อาจใช้เวลานานกว่าที่ต้องการ Proxy ทำหน้าที่เป็นชั้นกลางที่สามารถควบคุมการเปลี่ยนเส้นทาง Traffic ได้เร็วกว่าระบบ DNS ทั่วไปหลายเท่า
อีกหนึ่งสิ่งที่ได้จาก Proxy คือ ความสามารถในการจับข้อมูลเชิงลึกเกี่ยวกับ Pattern ของปัญหา เช่น Proxy สามารถบันทึกได้ว่า Error Type ไหนที่กำลังเพิ่มขึ้นผิดปกติ, Model ใดที่ตอบกลับช้าเกินมาตรฐาน, หรือว่ามี Region ไหนที่ Bandwidth เริ่มหนาแน่นจนใกล้จะกระทบคุณภาพการให้บริการ ทำให้ทีม Site Reliability Engineering (SRE) ของ Copilot สามารถเตรียมการแก้ไขเชิงรุกได้ทันก่อนที่ผู้ใช้จะเริ่มรู้สึกถึงปัญหา
บทเรียนจากการลงทุนสร้าง Proxy Layer เองแทนการพึ่งพา Cloud Provider
หลังจากผ่านการสร้างและขยาย GitHub Copilot จนรองรับผู้ใช้ระดับโลกได้สำเร็จ ทีมได้ข้อสรุปที่น่าสนใจมากเกี่ยวกับการตัดสินใจสร้าง Copilot Proxy ด้วยตัวเอง แทนที่จะใช้แค่บริการจาก Azure หรือ Cloud Provider อื่นๆ แบบตรงๆ
ถ้าเรามองในเชิง Engineering หากเป้าหมายคือการทำให้ Latency ต่ำที่สุด หลายคนอาจคิดว่า ควร “ตัดคนกลาง” ออกให้หมด เหลือเพียง Client เชื่อมตรงไปยัง Azure โดยตรง จะเร็วที่สุด แต่ในความเป็นจริง กลับไม่ง่ายแบบนั้น เพราะมันมีปัญหาใหญ่สองเรื่องที่เราต้องแก้ไขเองหากไม่มี Proxy
เรื่องแรกคือ Authentication ถ้าให้ Client เชื่อมต่อ Azure โดยตรง เราต้องหาทางทำให้ Azure เข้าใจ OAuth Token ของ GitHub ซึ่งซับซ้อนกว่าการใช้ API Key ทั่วไปมาก แน่นอนว่ามันเป็นไปได้ แต่สุดท้ายก็จะทำให้ Azure ต้องสร้าง Layer พิเศษขึ้นมาเอง เพื่อรับ Token ของเราก่อนจะแปลงไปเป็น Token ที่ Azure เข้าใจ ซึ่งนั่นคือการสร้าง Proxy ซ้อนอยู่ใน Azure นั่นเอง แค่ซ่อนจากสายตาเราเท่านั้น
เรื่องที่สองคือ Observability หรือความสามารถในการมองเห็นและควบคุมการทำงานของระบบแบบละเอียด หากเชื่อมตรงกับ Azure จริงๆ เราจะเห็นแค่ Metrics ที่ Azure เลือกให้เราเห็นเท่านั้น ซึ่งส่วนใหญ่มักเป็นแค่ Request Count หรือ Error Rate คร่าวๆ ไม่มี Granularity หรือ Data Points ลึกพอที่จะจับปัญหาที่ซับซ้อน เช่น ปัญหา Cancel Request, ปัญหา Latency ที่กระจายไม่สม่ำเสมอ หรือปัญหา Model Drift ได้เลย
การตัดสินใจสร้าง Proxy ของตัวเองทำให้เราได้ควบคุมทุกอย่างไว้ในมือ ไม่ว่าจะเป็น Authentication, Authorization, Observability, Health Check หรือแม้แต่ Traffic Routing ทั้งหมด นอกจากนี้ เมื่อเราวาง Proxy และ Model ใน Region เดียวกัน ค่า Overhead ของการเพิ่ม “หนึ่ง hop” ของ Proxy กลายเป็นแทบไม่มีนัยสำคัญ เพราะ Inter-region Traffic ของ Azure นั้นคงที่และต่ำมาก จนสามารถมองข้ามได้ในทางปฏิบัติ
เมื่อมี Proxy แล้ว ทีม Copilot ยังสามารถตอบสนองต่อเหตุการณ์ฉุกเฉินได้ดีขึ้น ตัวอย่างเช่น วันหนึ่งเราเจอปัญหาว่า Model ใหม่ที่เพิ่ง Deploy มีปัญหา ชอบ generate token ผิดพลาด หากไม่มี Proxy ทางเดียวที่จะแก้ได้คือต้องรีบออก Client Patch ทั่วโลก ซึ่งใช้เวลานานและไม่มีทางแก้ได้ครบทุกคนในเวลาอันสั้น แต่ด้วย Proxy เราสามารถแทรก logic เข้าไป “ห้าม Model generate token แบบนั้น” ได้ทันที ทำให้ผู้ใช้ไม่รู้สึกถึงปัญหาเลยแม้แต่นิดเดียว และให้เวลาทีม Model ค่อยๆ แก้ไขระบบด้านหลังโดยไม่กดดัน
อีกเหตุการณ์หนึ่งที่สะท้อนประโยชน์ของ Proxy อย่างชัดเจน คือการเจอปัญหา “Fast Cancellation” ที่พูดถึงไปก่อนหน้านี้ การตรวจพบว่ามี Request ถูก Cancel ทันทีหลังส่งมาไม่กี่มิลลิวินาที เป็นสิ่งที่เราไม่มีทางมองเห็นได้เลยถ้าไม่มี Proxy นั่งอยู่กลางทาง และการเพิ่ม Filter เพื่อ Block Request ที่กำลังจะถูก Cancel ก็ทำให้เราประหยัดค่าใช้จ่าย Model API ลงไปได้อย่างมหาศาลในระยะยาว
ข้อคิดสำหรับทีมที่กำลังพิจารณาจะสร้าง Proxy ของตัวเอง
บทเรียนสำคัญที่สุดจาก GitHub Copilot คือ “อย่าเพิ่งรีบสรุปว่าอะไรที่ดูเหมือน Middleware เป็น overhead” เพราะในบางกรณี Middleware อย่าง Proxy นี่แหละที่ทำให้ระบบสามารถ scale ได้อย่างยั่งยืนทั้งในแง่ performance, reliability และ operational agility
แต่การจะตัดสินใจสร้างเองไม่ใช่เรื่องง่าย ต้องชั่งน้ำหนักว่าการลงทุนสร้าง Proxy จะให้ผลตอบแทนมากพอหรือไม่ ต้องพิจารณาว่า Service ที่กำลังสร้างมีความต้องการพิเศษเรื่อง Authentication, Observability, Traffic Management หรือ Latency Optimization มากน้อยแค่ไหน
ถ้า Service ของคุณเป็นแค่ Web App ทั่วไปที่โหลดหน้าเว็บ แล้วจบในไม่กี่วินาที การทำ Proxy อาจไม่คุ้มค่า แต่ถ้าเป็น Service ที่มี Traffic แบบ Realtime, มี LLM หรือ AI inference หนักๆ อยู่ข้างหลัง หรือมีผู้ใช้จากทั่วโลกที่ต้องการ Latency ต่ำจริงๆ การสร้าง Proxy Layer ขึ้นมาเองอาจเป็นการลงทุนที่คุ้มค่าที่สุดในระยะยาว
GitHub Copilot ยังสรุปเพิ่มอีกว่า ในอนาคต HTTP/2 และ HTTP/3 จะกลายเป็นมาตรฐานใหม่ของระบบที่ต้องการความเร็วสูง การเข้าใจว่า Protocol เหล่านี้ทำงานอย่างไรตั้งแต่พื้นฐานจนถึงระดับ connection management เป็นสิ่งที่ทีมพัฒนาควรลงทุนเรียนรู้ ไม่ใช่เพียงเพื่อ optimization แต่เพื่อความอยู่รอดในยุคที่ผู้ใช้คาดหวังคุณภาพการเชื่อมต่อระดับใกล้เคียง local experience แม้ว่าจะเชื่อมข้ามทวีปก็ตาม
เส้นทางการสร้าง GitHub Copilot Proxy และบทเรียนเพื่ออนาคต
หลังจากที่ทีม GitHub ลงแรงสร้าง Copilot Proxy และเดินทางผ่านทั้งความท้าทายทางเทคนิค การจัดการ Traffic ทั่วโลก และการ Optimize ระบบเพื่อรองรับผู้ใช้ระดับหลายร้อยล้านคน วันนี้เราสามารถพูดได้เต็มปากว่าการลงทุนครั้งนี้ “คุ้มค่าเกินคาด”
Proxy กลายเป็นมากกว่าตัวกลางธรรมดา มันคือศูนย์กลางที่ช่วยให้ Copilot รองรับความต้องการที่เปลี่ยนแปลงตลอดเวลา ไม่ว่าจะเป็นการแก้ไขปัญหาที่ฝั่ง Client ได้ทันทีโดยไม่ต้องรอ Rollout Version ใหม่ การตรวจจับและตอบสนองต่อ Pattern ของปัญหาอย่าง Fast Cancellation การสร้าง Self-healing System ที่ทำให้เหตุการณ์ล่มระดับทวีปกลายเป็นแค่ Alert เล็กๆ หรือการทำ A/B Testing, Traffic Splitting, Canary Deployment ได้โดยไม่รบกวนผู้ใช้แม้แต่น้อย
บทเรียนที่ทีม GitHub อยากส่งต่อคือ การออกแบบระบบที่ดีไม่ใช่แค่เรื่องของการเขียนโค้ดที่ดีที่สุด หรือการเลือกใช้ Cloud Provider ที่แพงที่สุด แต่คือการเข้าใจว่าระบบจะเติบโตอย่างไรในอนาคต และลงทุนลงมือแก้ไขปัญหาในจุดที่สำคัญจริงๆ เท่านั้น Proxy อาจดูเหมือน Overhead เพิ่มเติมในช่วงแรก แต่ในระยะยาว มันกลายเป็นหัวใจของการรักษาความเสถียร ความเร็ว และคุณภาพบริการในระดับที่ทำให้ Copilot แตกต่างจากบริการทั่วไป
การเลือกใช้ HTTP/2 อย่างถูกต้องในทุกระดับ ตั้งแต่ Client, Proxy, ไปจนถึง Model Server เป็นอีกก้าวที่สำคัญ HTTP/2 ไม่ได้เป็นแค่เรื่องของความเร็วเท่านั้น แต่ยังเป็นพื้นฐานที่ทำให้การยกเลิก Request แบบละเอียดเป็นไปได้ ช่วยลดภาระงานที่สูญเปล่าในระบบได้มหาศาล การเข้าใจและใช้ประโยชน์จาก Protocol ใหม่อย่าง HTTP/2 หรือ HTTP/3 อย่างเต็มที่ คือทักษะที่ทุกทีมที่ทำ Distributed System ยุคใหม่ควรให้ความสำคัญ
สุดท้าย การสร้างระบบที่ดีไม่ใช่แค่การทำตาม Best Practice ที่คนอื่นเขียนไว้ แต่คือการเข้าใจบริบทของปัญหาของตัวเอง เลือกลงทุนในจุดที่มีโอกาสสร้างความแตกต่างที่จับต้องได้ เหมือนอย่างที่ทีม Copilot ลงทุนสร้าง Proxy Layer ขึ้นมาเอง จนกลายเป็นหนึ่งในหัวใจสำคัญที่ทำให้ GitHub Copilot เป็นบริการ code completion ที่ดีที่สุดในโลกใบนี้ ณ เวลานี้