
Slack: รัน 10 billion Cron Jobs ยังไงไม่ให้พัง!
Cron คืออะไร และ Slack ใช้ Cron อย่างไร?
Cron เป็น command line utility ที่ใช้ในการ schedule script หรือ job ให้ทำงานตามเวลาที่กำหนด เป็นมาตรฐานที่ใช้อย่างแพร่หลายในอุตสาหกรรมสำหรับการทำ Maintenance หรือ Administration Task ต่างๆ เช่น Cleanup ฐานข้อมูล, การรันรายงาน, การส่งการแจ้งเตือนแบบอัตโนมัติ
ที่ Slack ระบบ Cron มีบทบาทสำคัญอย่างยิ่ง เพราะมันอยู่เบื้องหลังการทำงานของหลายฟีเจอร์ในตัวผลิตภัณฑ์ เช่น Slack reminders, การส่ง email notifications, การทำ status cleanup, และการตั้งเวลาส่งข้อความ (scheduled send). ฟีเจอร์เหล่านี้ล้วนแล้วแต่ต้องทำงานตามเวลาเป๊ะๆ เพราะถ้ามีข้อผิดพลาดอย่างเช่น reminder ไม่ทำงาน ความเชื่อมั่นที่ผู้ใช้มีต่อ Slack จะลดลงทันที
นอกจากฟีเจอร์ของผลิตภัณฑ์แล้ว ระบบ Cron ยังถูกใช้สำหรับงาน Maintenance พื้นฐาน เช่น การทำ Database Cleanup และการเก็บข้อมูล Analytics ที่ต้องทำเป็นประจำทุกวันหรือทุกเดือนโดยอัตโนมัติ
ขนาดของระบบ Cron ที่ Slack
จำนวนผู้ใช้ของ Slack อยู่ที่ประมาณ 39 ล้าน Daily Active Users หรือถ้านับแบบแป๊ะ ๆ เลยก็ประมาณ 38.8 ล้าน ตัวเลขนี้หมายถึงผู้ใช้หลายสิบล้านคนที่พึ่งพา Slack ในการทำงานทุกวัน และคาดหวังว่า Slack ต้องทำงานได้อย่างราบรื่นไม่มีสะดุด
ภายในระบบมี Cron Scripts ประมาณ 385 ตัว และแต่ละตัวถูกรันเฉลี่ยประมาณ 2,000 ครั้งต่อชั่วโมง รวมแล้วแต่ละปีจะมีการ Execute Scripts เหล่านี้ประมาณ 20 ล้านครั้ง เป็นตัวเลขที่สูงมาก และต้องการระบบที่เชื่อถือได้จริงๆ
Lacacy Archtecture: Single Node Cron Box

เป็นเวลากว่า 10 ปี ที่ Slack ใช้ระบบแบบง่ายมากในการจัดการ Cron ทั้งหมด นั่นคือมีเพียงเซิร์ฟเวอร์เครื่องเดียวที่รันอยู่บน AWS ซึ่งภายในมี crontab ที่ไล่เรียก scripts ทั้งหมด
ทุกครั้งที่มี script เพิ่มขึ้น หรือมีความต้องการ memory สูงขึ้น Slack ก็จะเลือกวิธีแก้ปัญหาง่ายๆ คือการ “ซื้อเครื่องที่ใหญ่ขึ้น” (Vertical Scaling) เรื่อยๆ เซิร์ฟเวอร์เครื่องเดียวนี้ต้องแบกงานสำคัญระดับที่หากล่ม ก็ส่งผลต่อผลิตภัณฑ์ทันที
ข้อเสียที่ชัดเจนที่สุดของระบบเก่า คือเวลาที่ต้องทำ Security Patch ต้องมี Engineer คนหนึ่งรับผิดชอบเตรียมเครื่องใหม่ แล้วย้ายงานจากเครื่องเก่าไปยังเครื่องใหม่แบบรวดเร็วมาก เพื่อป้องกันปัญหาการรันซ้ำ หรือพลาดงานสำคัญ เป็นภาระที่ทั้งเครียดและเสี่ยงสูง และด้วยความที่ระบบนี้ถูกสร้างมาตั้งแต่ยุคแรกๆ มีแต่ความรู้เก่าๆ ที่ไม่มีเอกสารชัดเจน ทำให้ไม่มีใครอยากดูแลมันอีกต่อไป
สิ่งที่กระตุ้นให้ต้องรีบเปลี่ยนระบบจริงๆ คือในปีหนึ่ง Slack เจอ Incident ถึง 11 ครั้งที่เกี่ยวข้องกับเจ้า Cron Box เครื่องเดียวนี้ ทุกคนเริ่มเบื่อหน่าย และเห็นพ้องต้องกันว่า
“เราต้องการบางสิ่งที่ดีกว่า”
New Archtecture: Distributed Cron System
การแก้ปัญหาของคือการสร้างระบบใหม่ทั้งหมด ให้เป็น Distributed System ที่สามารถรองรับงานขนาดใหญ่ และลดภาระ Maintenance ลงได้
แนวทางที่เลือกคือการใช้ Job Execution Platform ที่มีอยู่แล้ว นั่นคือระบบ Asynchronous Compute Platform ที่แต่เดิมรองรับการทำงานนับพันล้านงานต่อวันอยู่แล้ว เพียงแต่ระบบนี้ “ไม่มีการจัดการ Scheduling” ซึ่งเป็นสิ่งที่ Cron ต้องการ
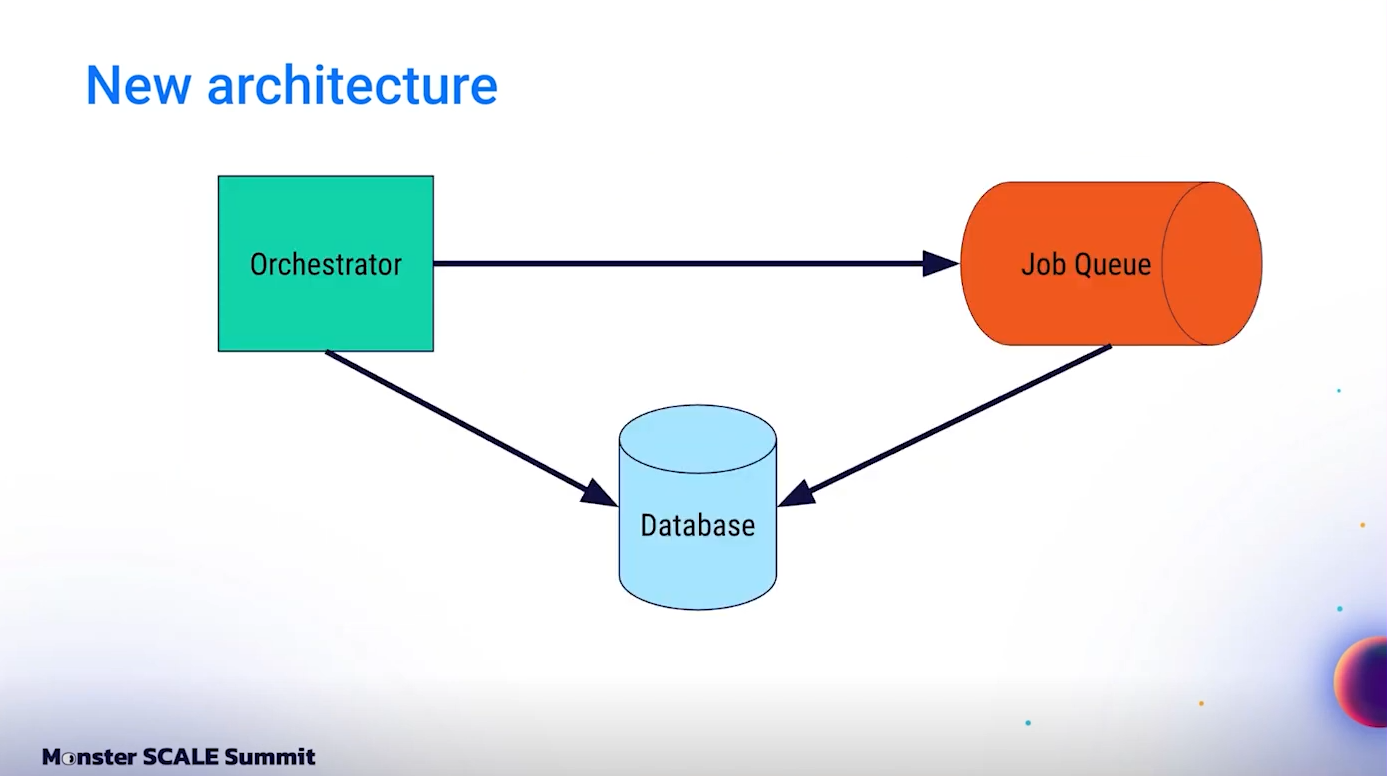
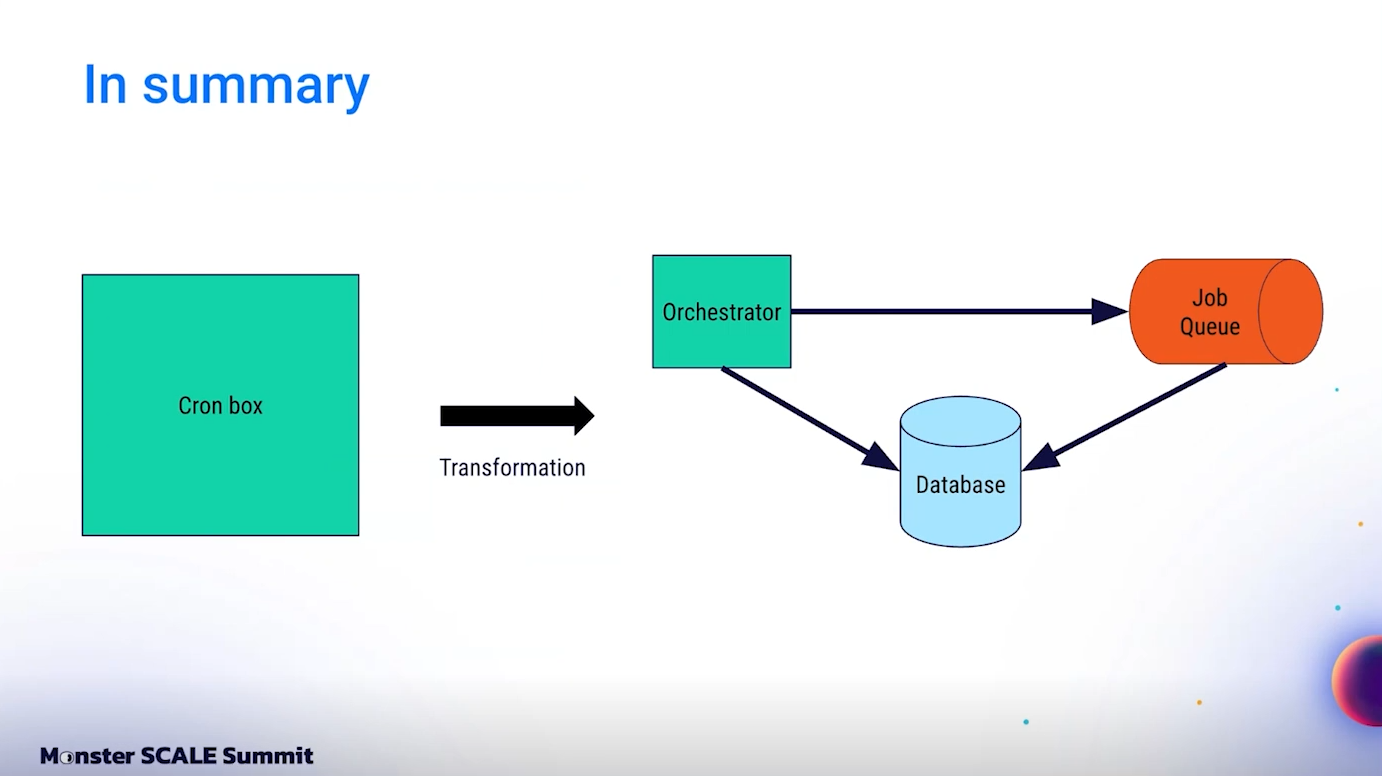
ดังนั้นจึงสร้าง Service ใหม่ที่เรียกว่า Orchestrator สำหรับทำ Scheduling โดยเฉพาะ และเพิ่ม Database สำหรับ Track การทำงานของ Jobs ให้สามารถตรวจสอบได้ง่าย
ในระบบใหม่มีองค์ประกอบหลัก 3 ส่วน คือ Orchestrator Service, Job Queue และ Database ซึ่งทั้งสามส่วนสื่อสารกันอย่างต่อเนื่องเพื่อจัดการงาน Cron ทั้งหมด
เบื้องหลัง Orchestrator Service ที่สร้าง Scheduling สำหรับ Distributed Cron
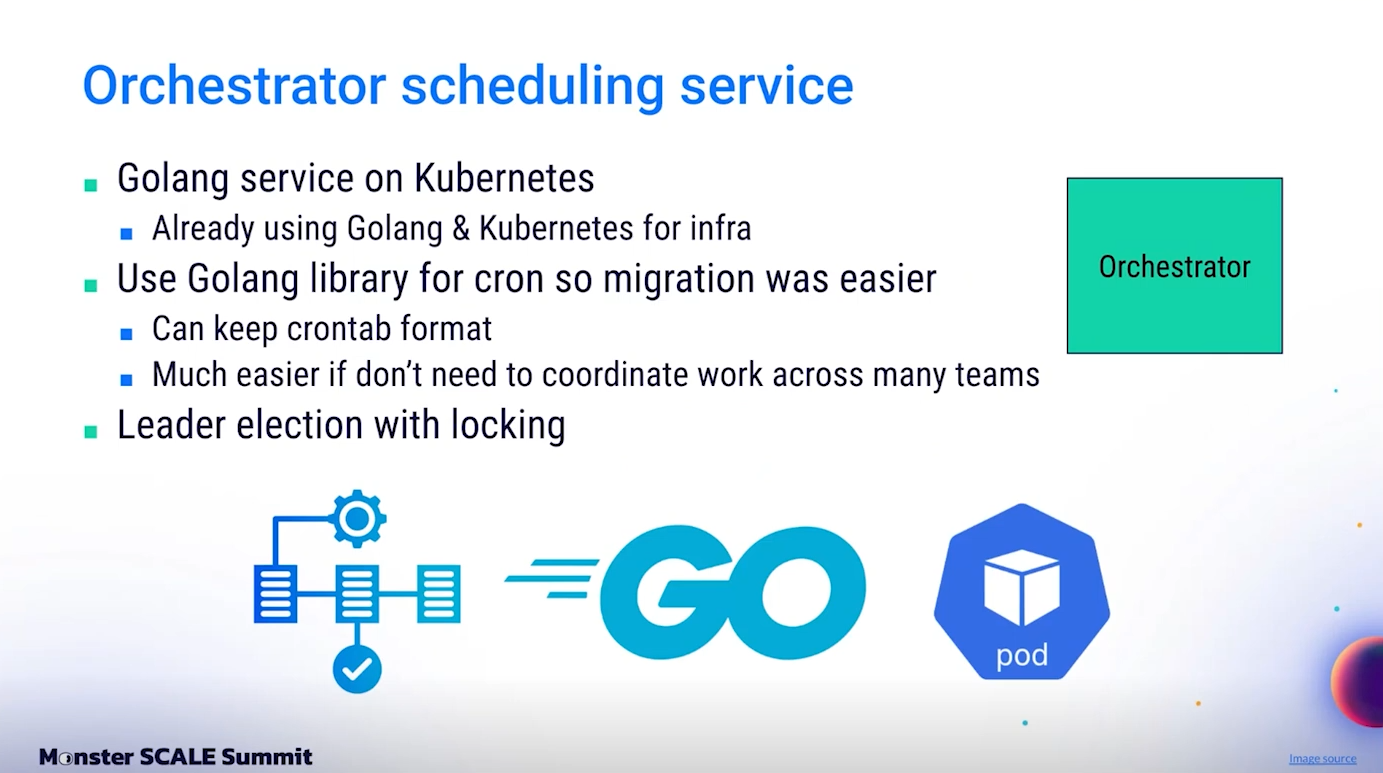
Orchestrator Service ที่สร้างขึ้น เป็นบริการที่พัฒนาด้วย Golang และรันอยู่บน Kubernetes เนื่องจากทีม Infrastructure ของ Slack ใช้ Golang และ Kubernetes เป็นเทคโนโลยีหลักอยู่แล้ว การนำเทคโนโลยีที่เราคุ้นเคยดีมาใช้ จึงช่วยลดภาระการดูแลรักษาในระยะยาวได้อย่างมาก และยังลดเวลาในการเทรนทีมใหม่หรือสอนคนที่เข้าเวร on-call อีกด้วย
ในโลกของ Golang มีไลบรารีที่ชื่อว่า robfig/cron ซึ่งเป็นไลบรารีสำหรับทำ Cron scheduling ที่มีคุณภาพสูงมาก เราจึงสามารถนำมันมาใช้งานใน Orchestrator ได้เลย โดยไม่ต้องสร้างระบบ timer หรือตัวจัดการเวลาขึ้นมาใหม่เองจากศูนย์ ช่วยให้การพัฒนา Orchestrator เป็นไปอย่างรวดเร็ว และ migration เป็นเรื่องที่ราบรื่น
สิ่งสำคัญที่เราพยายามเน้นที่สุดในการออกแบบระบบใหม่คือ "อย่าทำให้ทีมต้องไปแก้ไข Script เดิม" เพราะ Script ทั้ง 385 ตัวกระจายอยู่ในหลายทีม บางสคริปต์ไม่มีคนดูแลอย่างจริงจัง หากต้องให้ทุกทีมมา rewrite script ใหม่เพื่อย้ายมาใช้ระบบใหม่ โครงการนี้จะติดค้างอยู่กลางทางแน่นอน ดังนั้นเป้าหมายของ Orchestrator คือทำให้ Script เดิมทำงานต่อได้โดยไม่ต้องเปลี่ยนแปลงอะไรเลย
เพื่อให้ระบบ Distributed นี้มีเสถียรภาพ Orchestrator จึงใช้แนวทาง Leader Election เพื่อเลือก Node เดียวทำหน้าที่เป็น “ผู้นำ” จัดการ Scheduling
Leader Election และการตัดสินใจออกแบบสำคัญ
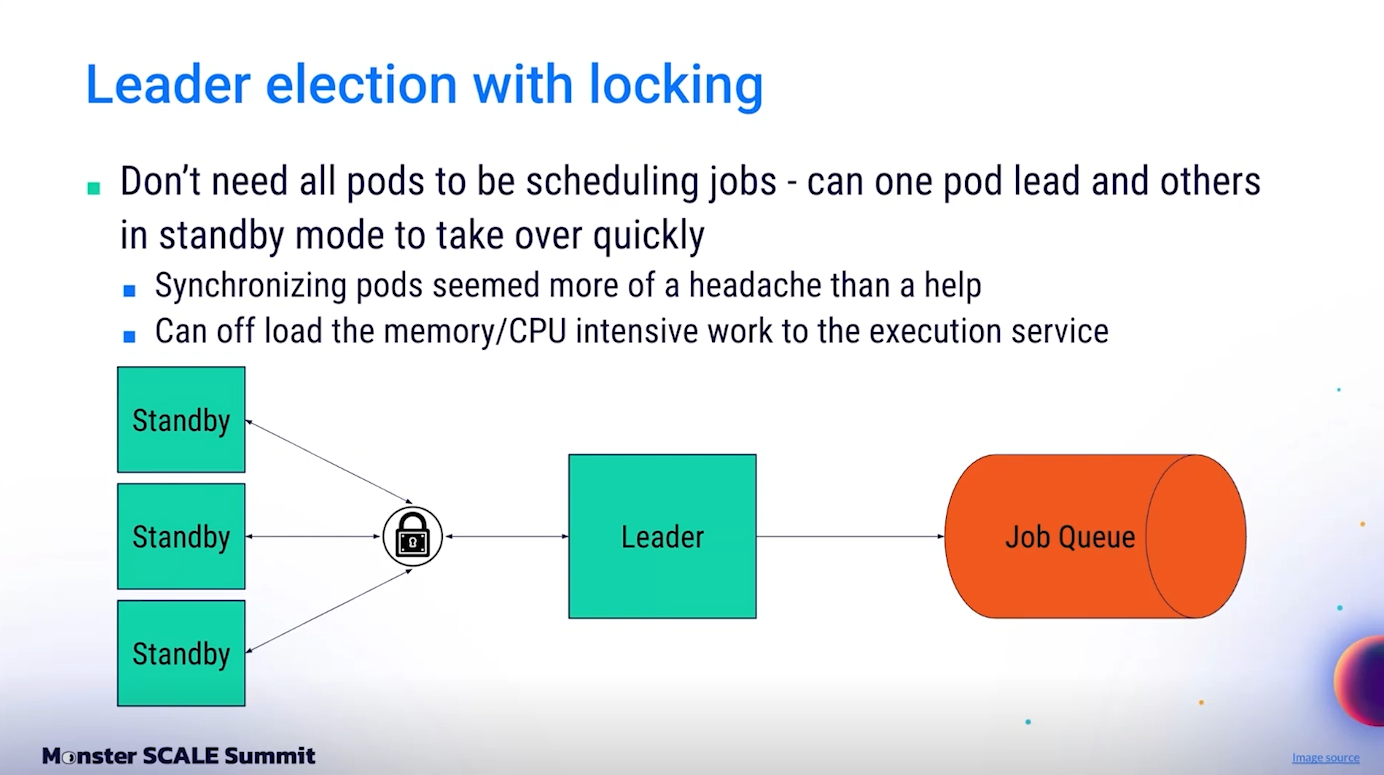
ในตอนออกแบบ Orchestrator มีทางเลือกสำคัญสองทาง ทางหนึ่งคือกระจาย Scripts ไปยังหลายๆ Pod แล้วให้แต่ละ Pod จัดการงานบางส่วน อีกทางหนึ่งคือให้มี Leader เพียงตัวเดียวคอยส่งงานทั้งหมดเข้าคิว
ทีมตัดสินใจเลือกแบบ “มี Leader ตัวเดียว” เพราะถ้าแจก Scripts ไปตาม Pod หลายๆ ตัว ต้องมีการ synchronize สถานะระหว่างกัน ซึ่งเพิ่มความซับซ้อนอย่างมาก และอาจทำให้เกิดปัญหาเช่น Network partition, Data race หรือ Deadlock ได้ง่าย
ที่สำคัญคือ ด้วยการมี Job Queue ขนาดใหญ่รองรับอยู่แล้ว Orchestrator ไม่จำเป็นต้องรัน Script เองเหมือนระบบเดิมอีกต่อไป มันแค่ “สร้าง request” ส่งไปยัง Job Queue เท่านั้น จึงใช้ resource ต่ำมาก ไม่มีความจำเป็นต้อง scale เป็นหลาย Pod เพื่อแบก Load การรัน Script จริง
ด้วยการเลือกแนวทางนี้ การทำ Leader Election และ Locking จึงกลายเป็นแค่เรื่องการเลือก Node ตัวหนึ่งใน Kubernetes Cluster แล้วทำให้ Node นั้นเป็นคนเดียวที่มีสิทธิ์ส่งงานเข้า Queue ในแต่ละช่วงเวลา
ผลลัพธ์ที่ได้คือ Orchestrator กลายเป็น Service ที่เบา, ง่ายต่อการดูแล, และลดจุดผิดพลาดในระบบได้อย่างมาก
เบื้องหลัง Job Queue: โครงสร้างระบบที่รองรับงาน 10 Billion ต่อวัน
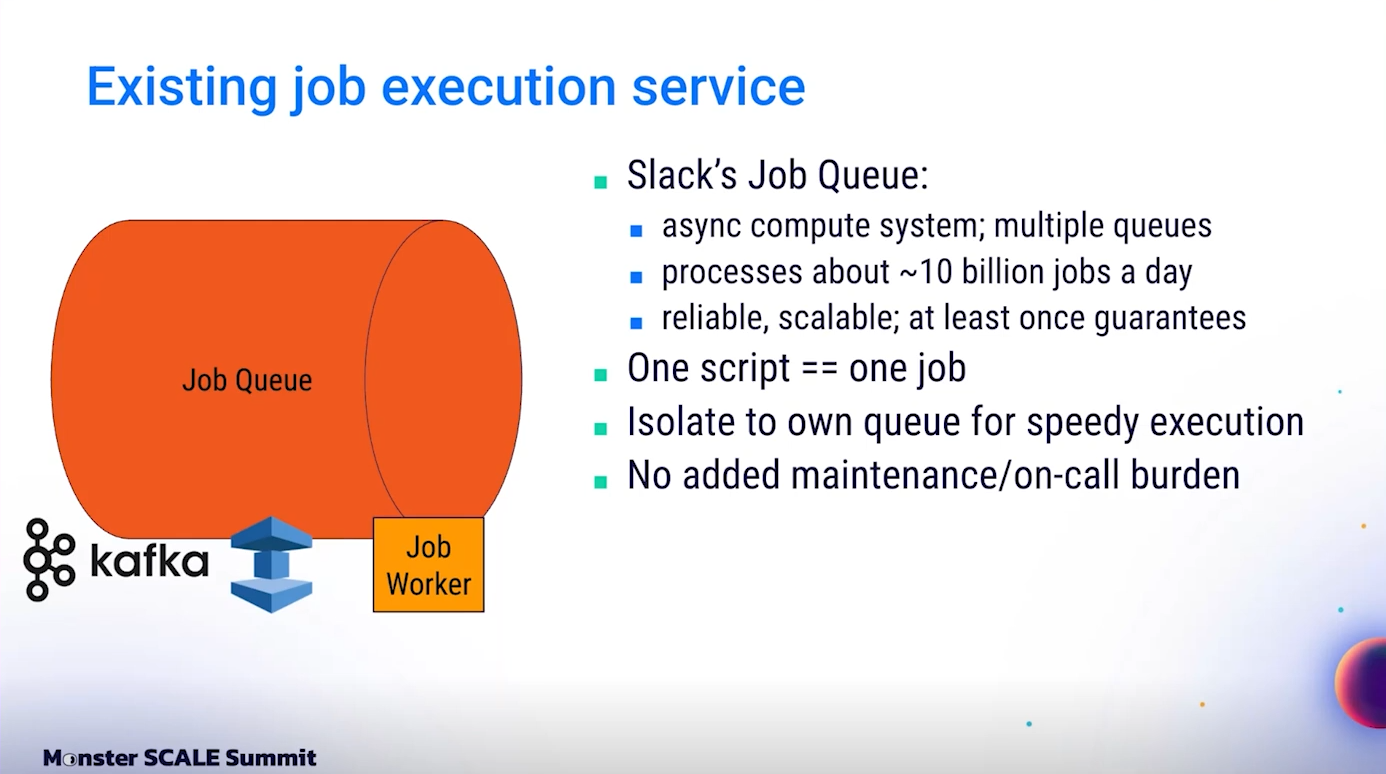
ระบบ Job Execution ของ Slack มีสถาปัตยกรรมที่น่าสนใจ มันประกอบด้วยหลายส่วนที่ทำงานร่วมกันอย่างแนบแน่น ได้แก่ Kafka, Redis และ EC2 Workers
วิธีการทำงานของระบบนี้คือ เมื่อมี Job ใหม่เข้ามา Job จะถูกส่งเข้า Kafka Topic เพื่อเก็บใน Queue อย่างเป็นระเบียบ เมื่อถึงเวลาที่กำหนดให้ Execute Job นั้น จะมี Process ที่ย้าย Job จาก Kafka เข้า Redis โดย Redis ทำหน้าที่เป็น temporary storage ที่สามารถทำ Bookkeeping และ Recovery ได้ กรณีที่งานบางอย่างอาจรันนานหลายวันหรือหลายสัปดาห์
สุดท้ายจริงๆ คืองานจริงจะถูกดึงไปประมวลผลโดย EC2 Workers ซึ่งเป็น Node ขนาดใหญ่ที่ทำงานเฉพาะการ execute jobs เท่านั้น
ระบบนี้รองรับ มากกว่า 10 Billion job executions ต่อวัน อยู่แล้ว ดังนั้นการเพิ่ม Cron Jobs เข้าไปในระบบเดียวกันจึงไม่เป็นปัญหาเลย แม้ว่าเราจะมี Scripts มากมายที่รันหลายล้านครั้งต่อปี การเพิ่มโหลดแค่ไม่กี่ล้านครั้งต่อปีเข้าไปบน scale นี้ถือว่าน้อยมาก และแทบไม่ส่งผลกระทบใดๆ
ที่สำคัญคือ เพราะเราต่อยอดจาก Job Queue ที่มีอยู่แล้ว เราไม่จำเป็นต้องตั้งทีมใหม่เพื่อดูแลระบบ Cron เพิ่ม ไม่ต้องมี on-call เพิ่ม ไม่ต้องมี monitoring ใหม่ให้ยุ่งยาก ทุกอย่างใช้เครื่องมือเดิม ทีมเดิม ดูแลระบบเดิม เพิ่มเติมแค่ว่าเรานำ Cron Jobs มาฝากในระบบที่แข็งแรงนี้เท่านั้นเอง
การแปลง Scripts ให้เป็น Jobs โดยไม่ต้อง Rewrite
แม้ว่า Job Queue ของ Slack จะมีรูปแบบการเขียน Job เฉพาะตัวที่ต่างจาก Script Cron เดิม แต่ทีมก็หาทางแก้ได้อย่างชาญฉลาด โดยการสร้าง Wrapper Job ที่อ่าน configuration จากไฟล์ แล้วรัน Script เดิมได้โดยตรง
แต่ละ Script จึงถูก “ห่อ” ให้กลายเป็น Job ได้โดยไม่ต้องแก้ Script ภายในเลยแม้แต่นิดเดียว ทำให้ Migration ทำได้เร็ว ลดความเสี่ยง และทำให้เจ้าของ Script แต่ละทีมไม่ต้องเสียเวลาทำอะไรเพิ่มเติม
Slack ยังแยก Queue ของ Cron Scripts ออกมาต่างหากจาก Queue งานปกติ เพื่อให้มั่นใจได้ว่าปัญหาของงานอื่นๆ จะไม่กระทบกับ Cron Execution และยังควบคุม Monitoring ได้ง่ายขึ้น
เพิ่ม Database สำหรับ Job Tracking
อีกหนึ่งองค์ประกอบสำคัญที่เราเพิ่มเข้ามาในระบบใหม่ คือ Database สำหรับ Tracking ว่างานแต่ละชิ้นทำงานสำเร็จหรือไม่ สำเร็จเมื่อไร และมีปัญหาอะไรเกิดขึ้นบ้าง
ในระบบเก่า เวลาจะตรวจสอบว่ามี Job ไหนล้มเหลวหรือไม่ Engineer ที่อยู่เวรต้องไปไล่เปิด log ของเครื่อง Cron Box เพียงเครื่องเดียวทีละไฟล์ กระบวนการนี้ไม่เพียงแต่ยุ่งยากและน่าเบื่อ แต่ยังเสี่ยงอย่างมากที่จะพลาดปัญหาเล็กๆ ที่สะสมกลายเป็นปัญหาใหญ่ในอนาคต
เมื่อมี Database Job Status อย่างเป็นระบบ คนที่อยู่เวรสามารถเข้าไปดูข้อมูลได้ผ่าน Web UI แบบง่ายๆ เพียงไม่กี่คลิก พวกเขาสามารถตรวจสอบได้ทันทีว่า Job ไหนทำงานสำเร็จ, Job ไหนล้มเหลว, ล้มเหลวเมื่อไหร่ และทำไมจึงล้มเหลว การมีข้อมูลที่โปร่งใสแบบนี้ทำให้การดูแลระบบโดยรวมเบาลงมหาศาล ลดความเหนื่อยล้าของคน และลดจำนวน Mistake ที่เกิดจากการตรวจสอบผิดพลาดไปได้อย่างมาก
แม้ในช่วงแรกเราจะเลือกใช้ฐานข้อมูลที่ไม่เสถียรมากนัก ทำให้พบปัญหาบ้างหลัง Deploy แรกๆ แต่เมื่อเราเปลี่ยนมาใช้ฐานข้อมูลที่มีความเสถียรสูงขึ้น ทุกอย่างก็ราบรื่นไม่มีปัญหาอีกต่อไป
ภาพรวมการเปลี่ยนแปลง: จาก Single Box สู่ Distributed Cron System
เมื่อมองภาพรวม Slack เปลี่ยนระบบจากเดิมที่มีเพียง Single EC2 Node ทำงานทั้งหมด มาเป็นระบบ Distributed ที่มี 3 องค์ประกอบสำคัญ ได้แก่ Orchestrator Service สำหรับ Scheduling, Job Queue ขนาดใหญ่สำหรับ Execute งาน และ Database สำหรับ Tracking
แม้ว่าองค์ประกอบจะดูมากขึ้น แต่การดูแลระบบกลับง่ายขึ้นกว่าเดิม เพราะแต่ละส่วนถูกออกแบบมาอย่างชัดเจน มีการแยกความรับผิดชอบ และทำงานร่วมกันได้อย่างเป็นระบบ
Reliability เพิ่มขึ้นอย่างเห็นได้ชัด ทั้งในแง่การลดจำนวน Incident, การทำ Failover ได้ง่ายขึ้น และการทำ Observability ให้ลึกและละเอียดกว่าเดิมมหาศาล
ทำไมถึงไม่ใช้ Kubernetes CronJob?

คำถามยอดฮิตที่เจอเมื่อเล่าโปรเจกต์นี้ให้คนอื่นฟังคือ “แล้วทำไมไม่ใช้ Kubernetes CronJob ล่ะ?”
แน่นอนว่า Slack ใช้ Kubernetes อยู่แล้ว การใช้ CronJob ของ Kubernetes ดูเหมือนจะเป็นทางเลือกที่ง่ายและเหมาะสม แต่เมื่อวิเคราะห์ลึกๆ แล้ว มันมีปัญหาสำคัญด้าน Scale
ที่ Slack เรามีงาน Cron จำนวนมาก หากใช้ Kubernetes CronJob จริงๆ เราจะต้อง Spin Up Pod ใหม่ทุกครั้งที่มี Script รัน หมายความว่าเราจะมีการสร้าง Pod ถึงประมาณ 54,000 Pods ต่อวัน แค่เพื่อรัน Cron Scripts เท่านั้น
ตัวเลขนี้ใหญ่เกินไปอย่างมากสำหรับ Cluster ทั่วไป ปัญหาที่ตามมาจะได้แก่ Cluster Overload, ปัญหา Resource Exhaustion, การต้องลงทุนทำ Auto-scaling และ Cluster Autoscaler แบบพิเศษ รวมถึงการต้องสร้าง tooling ใหม่เพื่อรองรับ Load ระดับนี้
ทีมจึงพิจารณาแล้วว่า การต่อยอดจาก Job Execution Platform ที่เรามีอยู่แล้วนั้นทั้งง่ายกว่า ประหยัดกว่า และเสี่ยงน้อยกว่ามาก
อีกทั้งการเลือกใช้ระบบเดิมยังทำให้เราไม่ต้องลงทุนเวลาทำ Migration scripts ใหม่, ไม่ต้อง Rewrite config, และไม่ต้องเพิ่มความรู้ความเข้าใจใหม่ให้กับทีม DevOps หรือ on-call engineer
ดังนั้น แม้ Kubernetes CronJob จะเป็นทางเลือกที่ดีสำหรับหลายๆ บริษัท แต่สำหรับ Slack ที่มี Scale ใหญ่ระดับนี้ มันไม่ใช่ทางเลือกที่คุ้มค่าที่สุด
หลังจาก Deploy ระบบใหม่: ผลลัพธ์ที่เปลี่ยนโลก
เราเริ่ม Deploy ระบบ Distributed Cron ใหม่เมื่อประมาณหนึ่งปีก่อน นับจากวันนั้นจนถึงปัจจุบัน ระบบได้รัน Cron Jobs สำเร็จไปแล้วมากกว่า 6 ล้านครั้ง โดยไม่มี Incident ใหญ่แม้แต่ครั้งเดียว
การไม่มี Incident อาจวัดผลได้ยาก เพราะมันคือ “สิ่งที่ไม่เกิดขึ้น” แต่ทุกคนในทีมเห็นชัดเจนว่าคุณภาพชีวิตดีขึ้นอย่างมหาศาล ไม่ต้องอยู่เวรแบบเครียดๆ ทุกวัน ไม่ต้องลุ้นว่าจะต้องวิ่งแก้ไขระบบกลางดึก หรือเหนื่อยใจกับการดูแล Cron Box เครื่องเดียวอีกต่อไป
เมื่อเทียบกับปีที่ต้องเจอ Incident 11 ครั้ง การไม่มี Incident เลยเป็นเวลาข้ามปี ถือเป็นความสำเร็จที่ยิ่งใหญ่มาก
บทเรียนสำคัญจากโปรเจกต์นี้
สิ่งแรกที่ได้เรียนรู้คือ
ใช้สิ่งที่เรามี
แทนที่จะไปไล่หาเทคโนโลยีใหม่ตลอดเวลา การลงทุนต่อยอดจากระบบ Job Queue ที่เรามีอยู่แล้ว การใช้ Kubernetes ที่เรารู้จักดี การใช้ Golang ที่ทีมถนัด ล้วนแล้วแต่ทำให้โปรเจกต์เดินหน้าได้เร็วขึ้น น่าเชื่อถือขึ้น และง่ายต่อการ Maintenance ในระยะยาว
อีกบทเรียนสำคัญที่มักถูกมองข้ามคือ
การรักษาความเรียบง่าย
Slack สามารถพึ่งพาเพียง Cron Box เครื่องเดียวได้ถึงสิบปี แม้มันจะมีข้อจำกัดและปัญหา แต่มันก็ “เพียงพอ” สำหรับงานที่ต้องทำในช่วงเวลานั้น
ดังนั้น บางครั้งการสร้างระบบไม่จำเป็นต้องยิ่งใหญ่หรือซับซ้อนตั้งแต่วันแรก หากระบบเล็กๆ ง่ายๆ สามารถตอบโจทย์ได้ในเวลานั้น ก็ไม่มีความจำเป็นต้องรีบเปลี่ยนแปลง จนกว่าความต้องการจะโตมากพอจริงๆ แล้วค่อยยกระดับอย่างมีเป้าหมายเหมือนที่ Slack ทำ