
หลักการ Auto Scale ของ Kubernetes
Horizontal Pod Autoscaling
ใน Kubernetes เนี่ย มีของที่เรียกว่า HorizontalPodAutoscaler หรือเรียกสั้น ๆ ว่า HPA มันจะคอยปรับพวก workload resource (เช่น Deployment หรือ StatefulSet) แบบอัตโนมัติ เพื่อให้ระบบสามารถ scale ตามความต้องการใช้งานจริง
คำว่า horizontal scaling ก็คือการรับมือกับโหลดที่เพิ่มขึ้นด้วยการ เพิ่มจำนวน Pod เข้าไป อันนี้ต่างจาก vertical scaling ที่เป็นการเพิ่ม resource (เช่น CPU หรือ memory) ให้กับ Pod เดิมที่กำลังรันอยู่
ถ้าโหลดลดลง แล้วจำนวน Pod เกินค่าต่ำสุดที่เรากำหนดไว้ HPA ก็จะสั่งให้ resource ที่ดูแลอยู่ (เช่น Deployment หรือ StatefulSet) ลดจำนวน Pod ลง
แต่ต้องบอกก่อนว่า HPA จะไม่ทำงานกับ object ที่ scale ไม่ได้ เช่น DaemonSet นะ
จริง ๆ แล้ว HPA มันถูกสร้างเป็นทั้ง Kubernetes API resource และ controller ที่รันอยู่ใน control plane Resource จะกำหนดว่า controller ต้องทำงานยังไง ส่วนตัว controller เองมันจะคอยดู metric ต่าง ๆ เช่น average CPU utilization, average memory usage หรือแม้แต่ custom metric ที่เราตั้งเอง แล้วค่อย ๆ ปรับ scale ให้เหมาะกับสถานการณ์
HorizontalPodAutoscaler ทำงานยังไง?
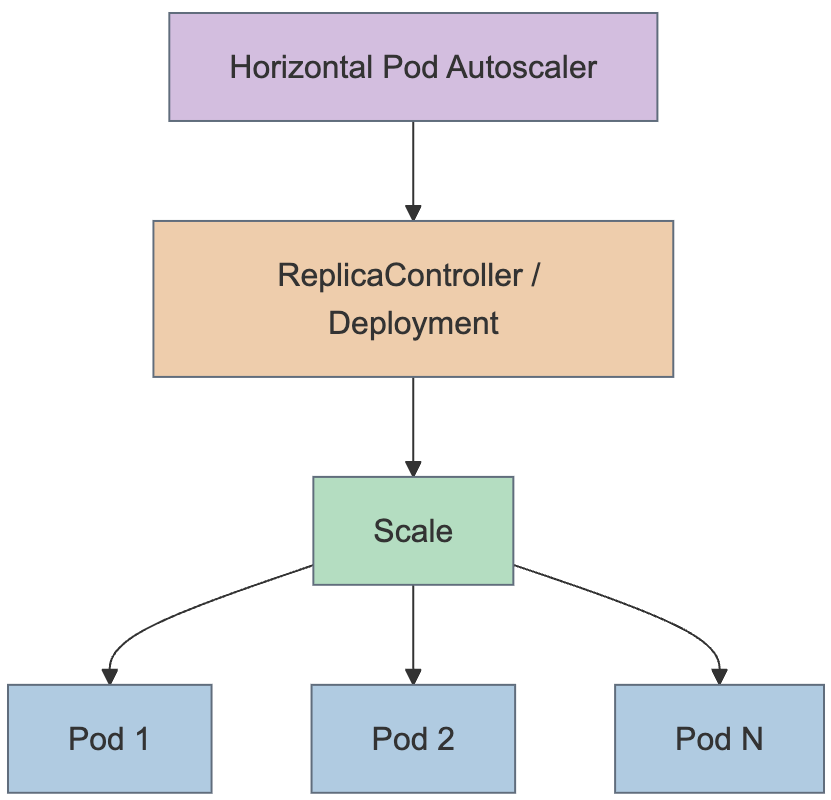 Figure 1: HorizontalPodAutoscaler คุม scale ของ Deployment และ ReplicaSet
Figure 1: HorizontalPodAutoscaler คุม scale ของ Deployment และ ReplicaSet
Kubernetes ใช้กลไกของ horizontal pod autoscaling เป็น control loop ที่รันแบบเป็นช่วง ๆ (ไม่ได้รันตลอดเวลา)
ช่วงเวลาที่มันจะ sync แต่ละครั้ง ถูกตั้งค่าไว้ด้วย --horizontal-pod-autoscaler-sync-period ใน kube-controller-manager
(โดย default จะ sync ทุก ๆ 15 วินาที)
ในแต่ละรอบที่รัน controller manager จะไปเช็คการใช้งาน resource (resource utilization) โดยอิงจาก metric ที่ระบุไว้ใน HPA แต่ละตัว
มันจะไปหาว่า HPA นั้นกำลัง target resource อะไร (ผ่าน scaleTargetRef) แล้วดูว่า Pod ไหนบ้างที่เกี่ยวข้อง จาก .spec.selector ของ resource นั้น
จากนั้นก็ไปดึง metric มาจาก resource metrics API (ถ้าเป็น per-pod metric อย่าง CPU) หรือ custom metrics API (ถ้าเป็น metric แบบอื่น)
ถ้าเป็น per-pod resource metric (เช่น CPU) controller จะไปดึง metric จาก resource metrics API ของแต่ละ Pod ที่อยู่ใน scope ของ HPA ถ้ามีตั้ง target utilization ไว้ มันก็จะคำนวณออกมาเป็น percentage ของ resource request ที่ container ใน Pod นั้นใช้ แต่ถ้าตั้งเป็น target raw value ไว้ มันก็จะใช้ค่าจริง ๆ (raw metric) ตรง ๆ เลย จากนั้น controller จะเอาค่าเฉลี่ยของ utilization หรือ raw value (แล้วแต่กรณี) มาหา ratio เพื่อใช้ในการคำนวณว่าจะต้อง scale เป็นกี่ replica
ข้อควรระวัง: ถ้า container บางตัวใน Pod ไม่ได้กำหนด resource request ไว้เลย เช่น CPU utilization ก็จะไม่สามารถคำนวณได้ และ autoscaler ก็จะไม่ทำอะไรกับ metric นั้น
ถ้าเป็น per-pod custom metric controller ก็จะทำงานคล้ายกันกับ per-pod resource metric เลย แต่จะใช้ raw value ตรง ๆ แทนการแปลงเป็น percentage
ส่วน object metrics หรือ external metrics จะมี metric แค่ตัวเดียวที่อธิบาย object นั้น ๆ แล้วจะเอาไปเทียบกับ target value เพื่อคำนวณ ratio เหมือนกัน (ถ้าใช้ autoscaling API version v2 ก็สามารถตั้งให้หารด้วยจำนวน Pod ก่อนจะเทียบได้ด้วย)
การใช้งานทั่วไปของ HPA คือการตั้งให้ไปดึง metric จากพวก aggregated APIs อย่าง
metrics.k8s.iocustom.metrics.k8s.ioexternal.metrics.k8s.io
โดย metrics.k8s.io จะมาจาก Metrics Server ซึ่งต้องติดตั้งแยกต่างหาก (ไม่มาพร้อมกับ Kubernetes)
API เหล่านี้ก็จะมี ระดับความเสถียร (stability) และ สถานะการซัพพอร์ต (support status) ที่ต่างกันไป ซึ่ง API documentation ก็จะอธิบายไว้ชัด
ตัว HPA controller เองจะเข้าถึง resource ที่สามารถ scale ได้ เช่น Deployment หรือ StatefulSet
resource เหล่านี้จะมี subresource ที่ชื่อว่า scale ซึ่งเป็น interface สำหรับกำหนดจำนวน replica แบบ dynamic ได้
รายละเอียดของ Algorithm ที่ใช้ใน HorizontalPodAutoscaler
โดยพื้นฐานเลยนะ ตัว controller ของ HPA จะใช้สูตรคำนวณจาก อัตราส่วน (ratio) ระหว่างค่า metric ที่ต้องการ กับค่าที่เป็นอยู่ตอนนี้:
desiredReplicas = ceil(currentReplicas × currentMetricValue / desiredMetricValue)เช่น:
ถ้าตอนนี้ metric เป็น 200m แล้ว target คือ 100m → จะได้ 200 ÷ 100 = 2.0 → ก็จะ scale เพิ่มขึ้นเป็น 2 เท่า
แต่ถ้า metric เป็น 50m แทน → ก็จะได้ 50 ÷ 100 = 0.5 → scale ลดลงครึ่งนึง
แต่ถ้า ratio ใกล้ 1.0 มาก (โดย default คือ ±0.1) HPA จะ ไม่ scale อะไรเลย (เพื่อหลีกเลี่ยงการแกว่งของจำนวน Pod ที่ไม่จำเป็น)
การคำนวณ metric
ถ้าตั้งพวก targetAverageValue หรือ targetAverageUtilization ไว้
ระบบจะไปเอา metric จากทุก Pod ใน scope ของ HPA มาหาค่าเฉลี่ย → นั่นแหละคือ currentMetricValue
ก่อนจะตัดสินใจ scale หรือไม่ scale ระบบจะเช็คด้วยว่า
- metric ของ Pod ไหนขาดหายมั้ย
- Pod ไหน Ready บ้าง
- Pod ไหนกำลังจะถูกลบ (
deletionTimestampตั้งไว้แล้ว) หรือ fail → พวกนี้จะไม่เอามาคิด
ถ้า Pod ไหนยังไม่มี metric หรือยังไม่ Ready → จะถูก “พักไว้ก่อน” (set aside) แล้วค่อยมาคิดตอนท้าย
กรณี CPU ยังไม่ Ready
เวลา scale จาก CPU metric ถ้า Pod ไหนยังไม่ Ready (กำลัง start อยู่ หรือ unhealthy) หรือ metric ล่าสุดมาหลังจากที่ Pod ยังไม่พร้อม → จะไม่เอาค่านั้นมาใช้ทันที
Kubernetes เองก็มีข้อจำกัด มันไม่รู้เป๊ะ ๆ ว่า Pod ไหน Ready ครั้งแรกเมื่อไหร่ เลยต้องใช้วิธีประมาณเอา:
- ถ้า Pod ยังไม่ Ready และเพิ่ง Ready ไม่นาน (ภายใน
--horizontal-pod-autoscaler-initial-readiness-delay, default: 30 วินาที) → ถือว่า “ยังไม่ Ready” - หลังจาก Ready ไปแล้ว ถ้ามีการ Ready ใหม่ภายในช่วง
--horizontal-pod-autoscaler-cpu-initialization-period(default: 5 นาที) → ก็ถือว่าเป็น Ready แรก
พอรู้ว่า Pod ไหนใช้ได้บ้างแล้ว…
เราก็จะใช้พวก Pod ที่ผ่านการคัดกรองข้างบนมาคิด ratio จริง ๆ ถ้ามี metric หาย ระบบจะ คิดแบบระมัดระวัง:
- ถ้าจะ scale down → สมมติว่า Pod ที่ไม่มี metric ใช้ 100% ของ target
- ถ้าจะ scale up → สมมติว่าใช้ 0% ของ target แบบนี้จะช่วย ลดความรุนแรงของการ scale ผิด ๆ
ถ้ามี Pod ที่ยังไม่ Ready และเรากำลังจะ scale up → ก็สมมติว่า Pod พวกนี้ใช้ 0% เช่นกัน → ลดความเสี่ยงการ scale เยอะเกินไป
พอรวมทุกอย่างแล้ว ค่อย คำนวณ usage ratio ใหม่ ถ้า ratio ใหม่มันสั่งให้ scale กลับไปทางเดิม หรือใกล้ 1.0 เกินไป → ไม่ scale แต่ถ้าไม่ใช่ → ค่อย scale ตาม ratio ใหม่
หมายเหตุ: ค่า average utilization ที่โชว์ใน HPA status จะไม่เอา not-yet-ready กับ missing metric มารวม (คือยังโชว์ตามค่า raw เดิม)
ถ้ามีหลาย metric
ถ้าตั้ง HPA ให้ดู metric หลายอัน มันจะคำนวณแบบนี้ทีละอัน แล้วเลือกจำนวน Pod ที่ต้องการมากที่สุดมาใช้
แต่ถ้า metric บางตัว error หรือดึงมาไม่ได้ → แล้ว metric ที่ได้แนะนำให้ scale down → จะไม่ scale เลย (เพราะไม่มั่นใจ) แต่ถ้ามี metric ตัวใดตัวหนึ่งที่แนะนำให้ scale up → ก็ scale ได้ตามนั้น
สุดท้ายก่อนจะ scale จริง ๆ
ก่อนจะ scale จริง HPA จะบันทึกว่า “แนะนำให้ scale เท่าไหร่”
แล้วจะดู recommendation ทั้งหมดในช่วงเวลาหนึ่ง (window ที่ตั้งไว้) แล้วเลือก ค่าที่สูงที่สุดในช่วงนั้น
ค่า window นี้ตั้งได้ด้วย --horizontal-pod-autoscaler-downscale-stabilization (default คือ 5 นาที)
→ ช่วยให้ scale down ค่อย ๆ เป็นค่อย ๆ ไป ไม่ให้กระตุกขึ้นลงแรง ๆ เวลาค่า metric แกว่ง
ความเสถียรของการ scale workload
เวลาเราจัดการจำนวน replica ด้วย HorizontalPodAutoscaler บางครั้งจำนวน Pod อาจจะ ขึ้น ๆ ลง ๆ ตลอดเวลา เพราะ metric ที่ใช้มันเปลี่ยนแปลงอยู่เรื่อย ๆ อาการแบบนี้เรียกว่า thrashing หรือ flapping ก็ได้ คล้าย ๆ กับแนวคิดที่เรียกว่า hysteresis ในโลก cybernetics เลย
การ autoscale ระหว่าง rolling update
ใน Kubernetes เราสามารถทำ rolling update กับ Deployment ได้ ซึ่งตัว Deployment จะเป็นคนคุม ReplicaSets ที่อยู่ข้างใต้ให้เอง
ถ้าเรา config autoscaling ไว้กับ Deployment → เราจะผูก HorizontalPodAutoscaler เข้ากับ Deployment ตัวเดียว
จากนั้น HPA จะจัดการกับ field replicas ของ Deployment โดยตรง
พอมี rolling update เกิดขึ้น ตัว deployment controller จะจัดการให้ ReplicaSet รวมกันได้จำนวนที่เหมาะสมระหว่าง rollout และหลัง rollout จบ
แต่ถ้าเป็น StatefulSet ที่มี autoscaling → StatefulSet จะ คุม Pod โดยตรง ไม่มี ReplicaSet อยู่ตรงกลางแบบ Deployment
รองรับ resource metric
HPA สามารถ scale ได้ตาม resource usage ของ Pod ที่อยู่ใน scope ได้เลย
เวลาเรา define pod spec ต้องระบุ resource requests อย่าง CPU กับ memory ไว้ด้วยนะ
เพราะข้อมูลนี้ใช้ในการคำนวณ resource utilization และใช้เป็นตัวตัดสินใจให้ HPA scale ขึ้นหรือลง
ถ้าจะใช้การ scale แบบอิง utilization ของ resource ก็ต้องตั้ง metric แบบนี้:
type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60แบบนี้หมายความว่า HPA จะพยายาม รักษาค่าเฉลี่ย CPU utilization ของ Pod ทั้งกลุ่มไว้ที่ 60% Utilization = ปริมาณการใช้ resource จริง ÷ resource ที่ขอไว้ (request) ดูในหัวข้อ Algorithm จะมีรายละเอียดการคำนวณค่าเฉลี่ยให้
หมายเหตุ: เวลา HPA คำนวณ utilization มันจะ รวมการใช้ resource ของทุก container ใน Pod เข้าด้วยกัน เพราะงั้นตัวเลขสุดท้ายของ Pod อาจไม่สะท้อนการใช้ resource ของ container แต่ละตัวได้ชัดเจน
ผลคืออาจเกิดเคสแบบนี้ได้: container ตัวนึงใช้ resource หนักมาก แต่พอรวมกับ container อื่น ๆ แล้วค่าเฉลี่ยของทั้ง Pod ยังไม่เกิน threshold → HPA เลยไม่ยอม scale ออก
Container resource metrics
HorizontalPodAutoscaler (HPA) ยังรองรับการตั้งค่าแบบ container metric source ด้วยนะ พูดง่าย ๆ ก็คือ HPA สามารถดูการใช้ resource ของ container แยกแต่ละตัว ในกลุ่ม Pod ได้เลย เพื่อใช้เป็นตัวตัดสินในการ scale อันนี้ดีมาก เพราะเราสามารถเลือก track เฉพาะ container ที่สำคัญใน Pod ได้
ตัวอย่าง: สมมติเรามี web app อยู่ใน container หลัก และมี sidecar container สำหรับ logging เราสามารถตั้งให้ HPA scale ตาม CPU ของ web app container ได้เลย โดย ไม่สน ว่า sidecar ใช้ resource เท่าไหร่
ถ้าเราแก้ resource หลัก (เช่น Deployment) แล้วเพิ่ม container ใหม่เข้าไป ถ้าอยากให้ container ใหม่นั้นมีผลกับการ scale ด้วย → ก็ต้อง แก้ HPA spec ด้วย
แต่ถ้า container ที่เราระบุใน metric source
- ไม่ได้อยู่ใน Pod ทุกตัว (แค่บางตัวมี)
- หรือไม่มีอยู่เลยใน Pod ที่รันอยู่บางตัว
Pod เหล่านั้นจะถูก มองข้าม (ignored) แล้ว HPA จะคำนวณ recommendation ใหม่ ดูรายละเอียดเพิ่มได้ในหัวข้อ Algorithm
ถ้าอยากตั้ง HPA ให้ scale ตาม resource ของ container เฉพาะ ให้ใช้ metric แบบนี้:
type: ContainerResource
containerResource:
name: cpu
container: application
target:
type: Utilization
averageUtilization: 60ตัวอย่างข้างบน หมายความว่า:
HPA จะพยายาม scale ให้ CPU utilization ของ container ชื่อ application ในแต่ละ Pod เฉลี่ยอยู่ที่ 60%
หมายเหตุ:
ถ้าเราเปลี่ยนชื่อ container ที่ HPA กำลัง track อยู่ เพื่อให้ระบบยัง scale ได้ลื่น ๆ ระหว่าง rollout ให้ทำตามลำดับนี้:
-
ก่อน เปลี่ยนชื่อ container ใน resource หลัก (เช่น Deployment) → ไปอัปเดต HPA ก่อน ให้ track ทั้งชื่อใหม่และชื่อเก่าพร้อมกัน
-
พอ rollout เสร็จแล้ว → ค่อยไป ลบชื่อ container เก่า ออกจาก HPA spec
การตั้งค่าพฤติกรรมการ scale (Configurable scaling behavior)
ถ้าใช้ HorizontalPodAutoscaler API v2 เราจะสามารถใช้ field ที่ชื่อว่า behavior เพื่อกำหนดพฤติกรรมการ scale ขึ้น (scaleUp) และ scale ลง (scaleDown) แยกกันได้
โดยเราสามารถตั้งค่า scaling policies เพื่อควบคุมว่าเวลาจะ scale นั้น จะเพิ่มหรือลด replica ได้เร็วแค่ไหน นอกจากนี้ยังมี 2 ตัวช่วยที่ช่วยลดปัญหา flapping (scale ไปมาเร็วเกิน):
- การตั้ง stabilization window เพื่อให้จำนวน replica เปลี่ยนแบบ smooth
- การตั้ง tolerance เพื่อมองข้ามความผันผวนของ metric ที่น้อยมาก ๆ
Scaling policies
ใน behavior สามารถใส่ policy ได้หลายอันเลย
ถ้ามีหลาย policy ระบบจะเลือก policy ที่ “เปลี่ยนแปลงได้เยอะสุด” มาใช้โดย default
ตัวอย่าง config นี้สำหรับการ scaleDown:
behavior:
scaleDown:
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 10
periodSeconds: 60periodSecondsหมายถึงระยะเวลาที่ย้อนกลับไปดูว่า policy นี้ยัง valid อยู่ไหม (max = 1800 วินาที = 30 นาที)- policy แรก (Pods) บอกว่า: scale down ได้สูงสุด 4 ตัวต่อนาที
- policy ที่สอง (Percent) บอกว่า: scale down ได้ไม่เกิน 10% ของจำนวน Pod ทั้งหมดต่อนาที
เช่น ถ้ามี 80 Pods แล้วต้องการ scale ลง → รอบแรกจะลด 8 ตัว (10%) รอบต่อไปเหลือ 72 → 10% = 7.2 → ปัดขึ้นเป็น 8 พอจำนวน Pod เหลือ 40 หรือน้อยกว่า → จะเปลี่ยนมาใช้ policy แรก คือ ลดครั้งละ 4 ตัว
ถ้าอยากเปลี่ยนวิธีเลือก policy จาก default (เลือกตัวที่ scale ได้เยอะสุด)
สามารถใช้ field selectPolicy ได้ เช่น:
Min→ เลือก policy ที่เปลี่ยนได้น้อยสุดDisabled→ ปิดการ scale สำหรับทิศทางนั้นไปเลย (เช่น scaleDown ไม่ทำ)
Stabilization window
stabilization window เอาไว้ช่วยลดอาการ flapping เวลาค่า metric ขึ้น ๆ ลง ๆ เร็วเกินไป HPA จะใช้ window นี้ในการดูว่า “สภาพก่อนหน้าที่เหมาะสม” คืออะไร แล้วพยายามไม่เปลี่ยนแปลงบ่อยโดยไม่จำเป็น
ตัวอย่าง:
behavior:
scaleDown:
stabilizationWindowSeconds: 300อันนี้หมายถึง ถ้า metric บอกว่าควรจะลด Pod ระบบจะไปดูว่าในช่วง 5 นาทีที่ผ่านมา (300 วินาที) เคยมีการคำนวณว่าอยากได้กี่ Pod → แล้วเลือกค่าที่สูงที่สุดในช่วงนั้นมาใช้
หลักการนี้ช่วยให้ระบบ ไม่ scale ลงเร็วเกิน แล้วก็ต้อง สร้างกลับขึ้นมาใหม่อีกทันที เพราะ metric แกว่ง
Tolerance (ค่าความผันผวนที่มองข้ามได้)
**tolerance** คือค่า threshold สำหรับการเปลี่ยนแปลงของ metric ที่ใช้เป็นเกณฑ์ว่า จะไม่ scale ถ้าค่าที่เปลี่ยนมันน้อยเกินไป
พูดง่าย ๆ คือ ถ้าค่า metric มันแกว่งเล็กน้อยรอบ ๆ ค่าที่เราตั้งไว้ ระบบจะ ไม่ scale เพื่อให้ระบบนิ่งขึ้น ไม่ต้องปรับขึ้นลงบ่อยเกิน
ตัวอย่าง:
ถ้าเราตั้ง HPA ให้ target memory อยู่ที่ 100MiB แล้วตั้ง tolerance ไว้ที่ 5%:
behavior:
scaleUp:
tolerance: 0.05 # 5% tolerance สำหรับการ scale ขึ้นแบบนี้จะหมายความว่า HPA จะพิจารณา scale เฉพาะเมื่อการใช้ memory เกิน 105MiB (คือ 100 + 5%)
ถ้า ไม่ตั้งค่า tolerance เอง ระบบจะใช้ค่า default ทั่วทั้งคลัสเตอร์คือ 10%
เราสามารถแก้ default นี้ได้โดยใช้ flag:
--horizontal-pod-autoscaler-toleranceกับ kube-controller-manager (ตั้งผ่าน API ไม่ได้นะ)
Default Behavior
เวลาใช้ HPA แบบ custom ไม่จำเป็นต้องตั้งทุก field ก็ได้ ตั้งเฉพาะค่าที่อยากปรับ ค่าอื่น ๆ จะใช้ default เดิมจาก HPA algorithm
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max-
scale down: window = 300 วินาที (หรือใช้ค่าจาก
--horizontal-pod-autoscaler-downscale-stabilizationก็ได้) และ policy บอกว่า scale down ได้ 100% → หมายถึงลดได้จนถึงจำนวนขั้นต่ำที่อนุญาต -
scale up: ไม่มี stabilization window → metric มาปุ๊บก็ scale เลย scale ได้สูงสุด 4 Pods หรือ 100% ทุก ๆ 15 วินาที (แล้วแต่ค่าที่มากกว่า)
ตัวอย่างการ config แบบต่าง ๆ
- เปลี่ยน stabilization window ของการ scale down ให้เป็น 1 นาที:
behavior:
scaleDown:
stabilizationWindowSeconds: 60- จำกัด rate การ scale down ไม่ให้เกิน 10% ต่อนาที:
behavior:
scaleDown:
policies:
- type: Percent
value: 10
periodSeconds: 60- จำกัดการลดไม่ให้เกิน 5 Pods ต่อนาที และเลือก policy ที่ลดได้น้อยที่สุด:
behavior:
scaleDown:
policies:
- type: Percent
value: 10
periodSeconds: 60
- type: Pods
value: 5
periodSeconds: 60
selectPolicy: Min- ปิดการ scale down ไปเลย:
behavior:
scaleDown:
selectPolicy: Disabled